| Session | Datum | Topic | Presenter |
|---|---|---|---|
Introduction |
|||
1 |
25.10.2023 |
Kick-Off |
Christoph Adrian |
01.11.2023 |
🎃 Holiday (No Lecture) |
||
2 |
08.11.2023 |
Einführung in DBD |
Christoph Adrian |
3 |
15.11.2023 |
🔨 Working with R |
Christoph Adrian |
🗣️ |
Presentations |
||
4 |
22.11.2023 |
📚 Media routines & habits |
Group C |
5 |
29.11.2023 |
~📚 Digital disconnection~ |
|
6 |
06.12.2023 |
📚 Digital disconnection |
Group A |
7 |
13.12.2023 |
📦 Data collection methods |
Group D |
8 |
20.12.2023 |
📦 Automatic text analysis 🎥 |
Group B |
🎄Christmas Break (No Lecture) |
|||
📂 Project |
Analysis of media content |
||
9 |
10.01.2024 |
🔨 Text as data |
Christoph Adrian |
10 |
17.01.2024 |
🔨 Automatic analysis of text in R |
Christoph Adrian |
11 |
24.01.2024 |
🔨 Q&A |
Christoph Adrian |
12 |
31.01.2024 |
📊 Presentation & Discussion |
All groups |
13 |
07.02.2024 |
🏁 Recap, Evaluation & Discussion |
Christoph Adrian |
🔨 Text as data in R
Session 09
10.01.2024
Looking at the discourse
The theoretical background: digital disconnection
Increasing trend towards more conscious use of digital media (devices), including (deliberate) non-use with the aim to restore or improve psychological well-being (among other factors)
But how do “we” talk (on Twitter) about digital detox/disconnection:
Is social media a 💊 drug, 👹 demon or 🍩 donut?

Biggest attention in 2016, steady decline thereafter
Distribution of tweets with reference to digital detox over time
Expand for full code
tweets_correct %>%
ggplot(aes(x = as.factor(year), fill = retweet_dy)) +
geom_bar() +
labs(
x = "",
y = "Number of tweets",
fill = "Is the tweet a retweet?"
) +
scale_fill_manual(values = c("#1DA1F2", "#004389")) +
theme_pubr() +
# add annotations
annotate(
"text",
x = 14, y = 55000,
label = "Increase of character limit from 140 to 280") +
geom_curve(
data = data.frame(
x = 14.2965001234837,y = 53507.2283841571,
xend = 11.5275706534335, yend = 45412.4966032138),
mapping = aes(x = x, y = y, xend = xend, yend = yend),
angle = 127L,
curvature = 0.28,
arrow = arrow(30L, unit(0.1, "inches"), "last", "closed"),
inherit.aes = FALSE)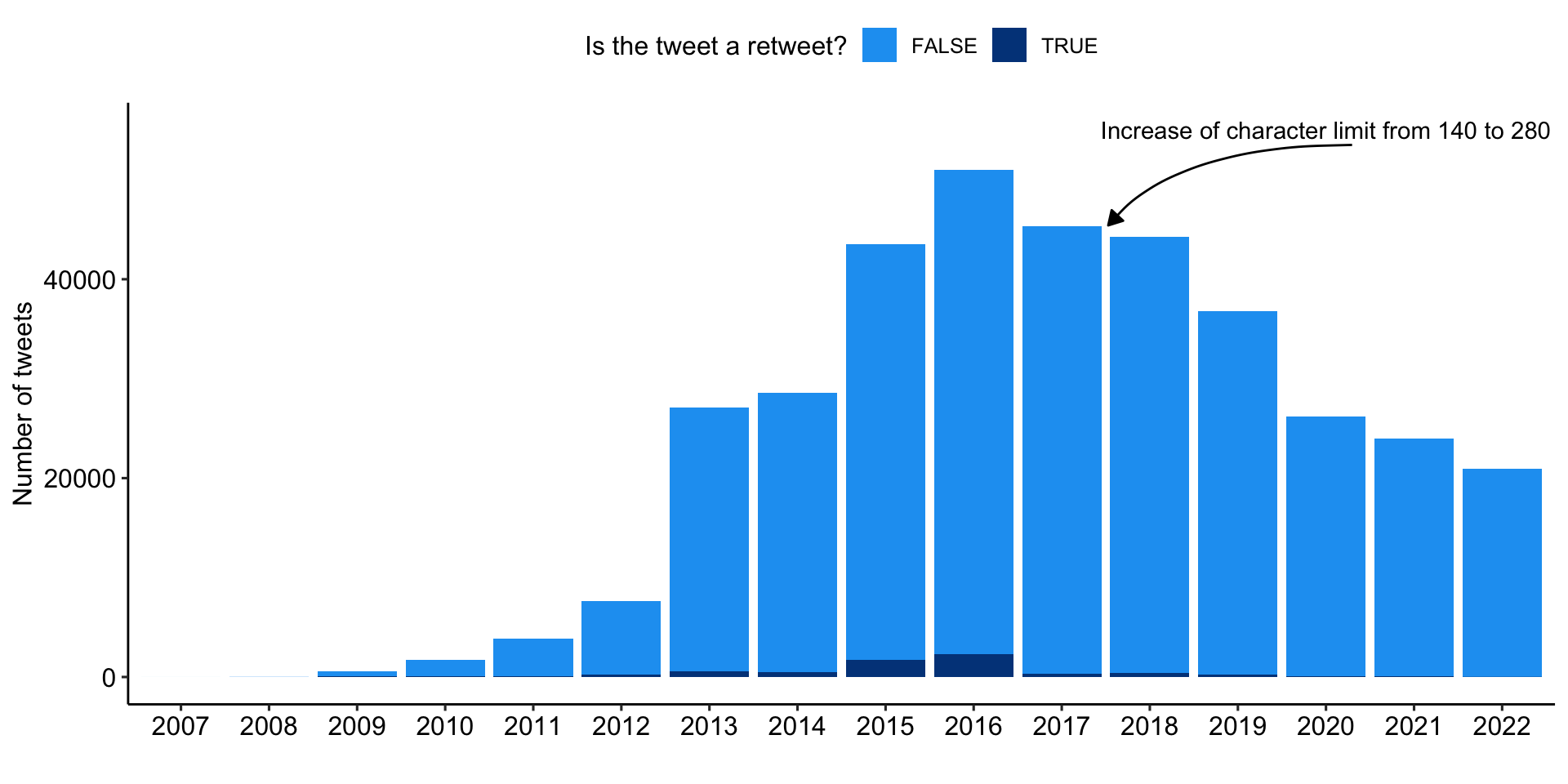
Building a shared vocabulary
Important terms & definitions

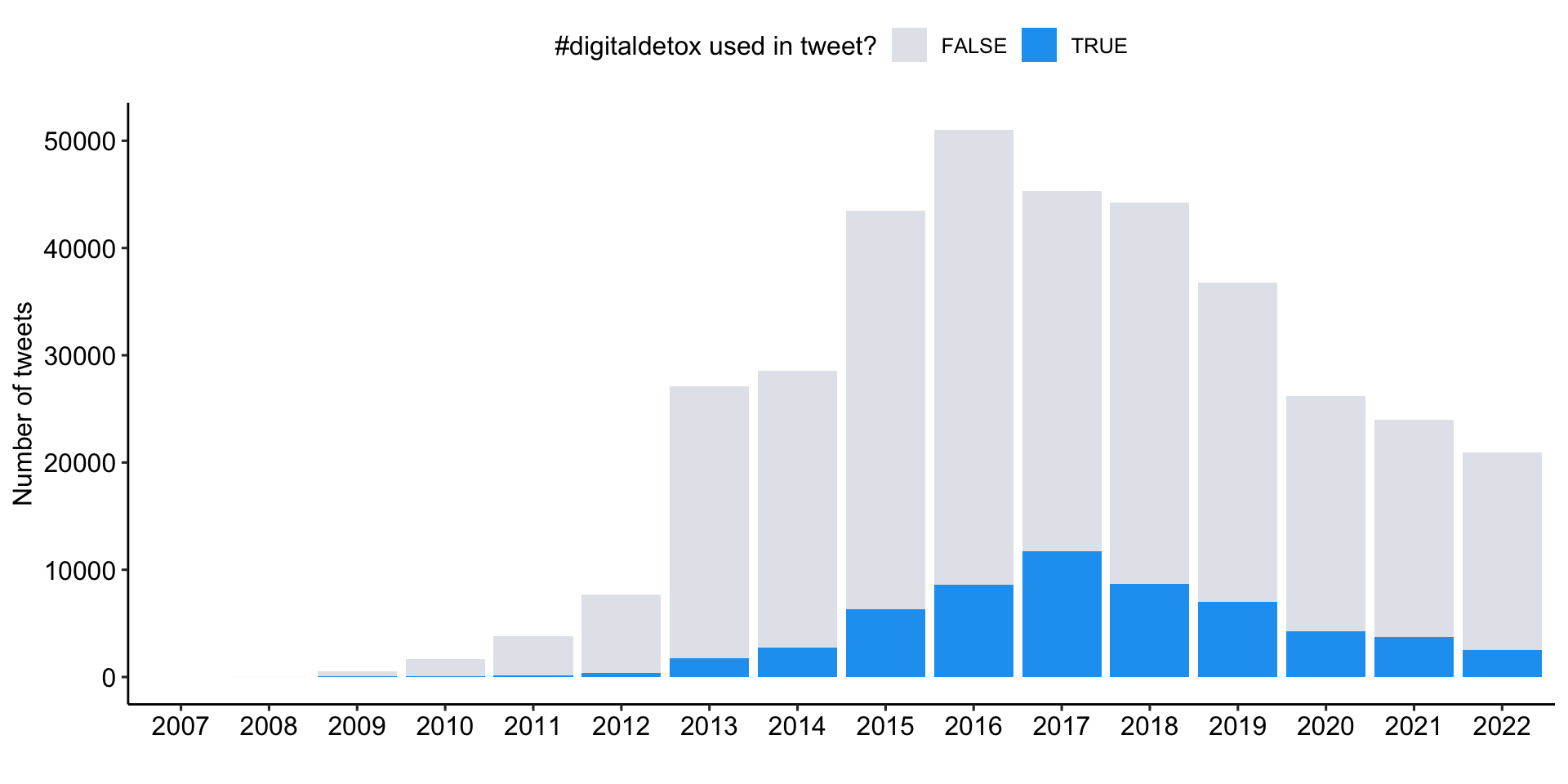
Explore tweets with #digitaldetox
Working through a typical text analysis using tidy data principles

- But: Tidy data has a specific structure:
- Each variable is a column
- Each observation is a row
- Each type of observational unit is a table.
- Thus the tidy text format is defined as a table with one-token-per-row (Silge & Robinson, 2017).
Focusing on #digitaldetox
Build a subsample
The (Unavoidable) Word Cloud
Visualization of Top 100 token

More than just single words
Modeling realtionships between words: n-grams and correlations
Many interesting text analyses are based on the relationships between words
- whether examining which words tend to follow others immediately (n-grams),
- or that tend to co-occur within the same documents (correlation)
Correlates of detox and digital
Display correlates for specific token
tweets_pairs_corr %>%
filter(
item1 %in% c("detox", "digital")
) %>%
group_by(item1) %>%
slice_max(correlation, n = 5) %>%
ungroup() %>%
mutate(
item2 = reorder(item2, correlation)
) %>%
ggplot(
aes(item2, correlation, fill = item1)
) +
geom_bar(stat = "identity") +
facet_wrap(~ item1, scales = "free") +
coord_flip() +
scale_fill_manual(
values = c("#C50F3C", "#04316A")) +
theme_pubr()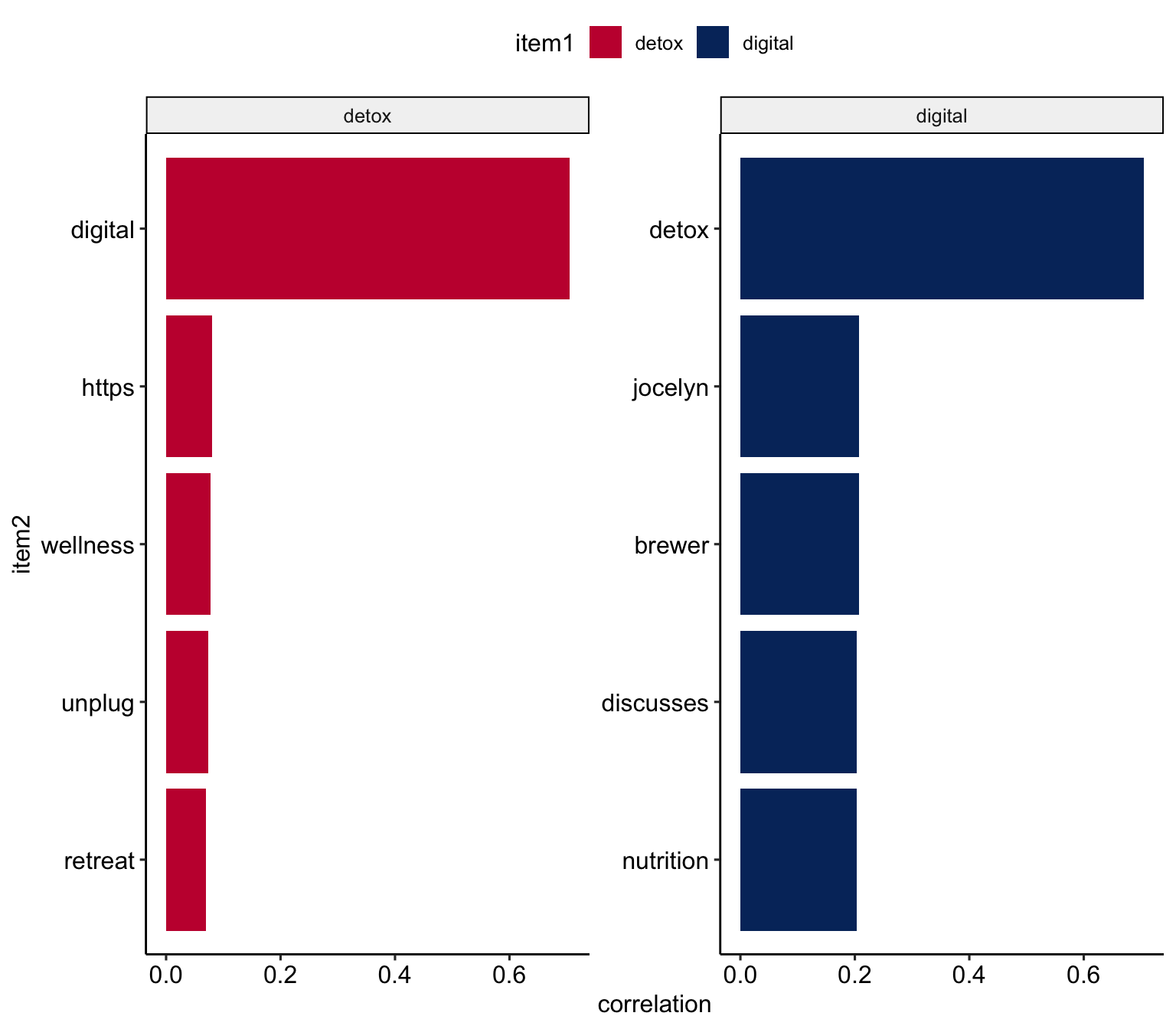
Let’s talk about sentiments
Dictionary based approach of text analysis
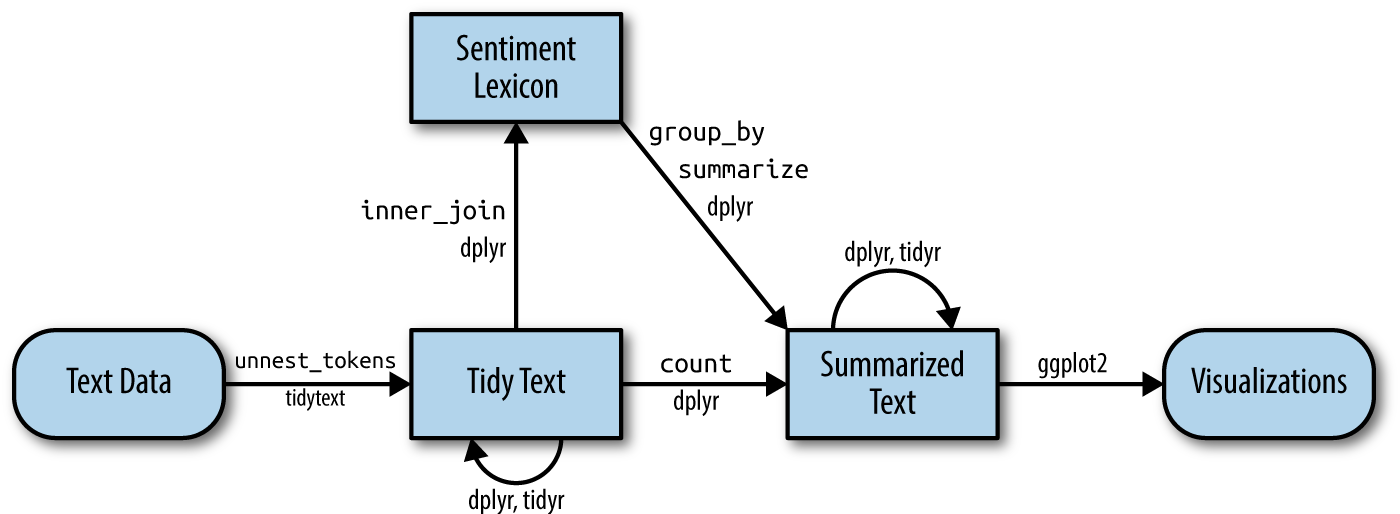
Atteveldt et al. (2021) argue that sentiment, in fact, are quite a complex concepts that are often hard to capture with dictionaries.
The meaning of “positive/negative”
Most commmon positive and negative words
tweets_sentiment_count <- tweets_tidy %>%
inner_join(
get_sentiments("bing"),
by = c("text" = "word"),
relationship = "many-to-many") %>%
count(text, sentiment)
# Preview
tweets_sentiment_count %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(text = reorder(text, n)) %>%
ggplot(aes(n, text, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(
~sentiment, scales = "free_y") +
labs(x = "Contribution to sentiment",
y = NULL) +
scale_fill_manual(
values = c("#C50F3C", "#007D29")) +
theme_pubr()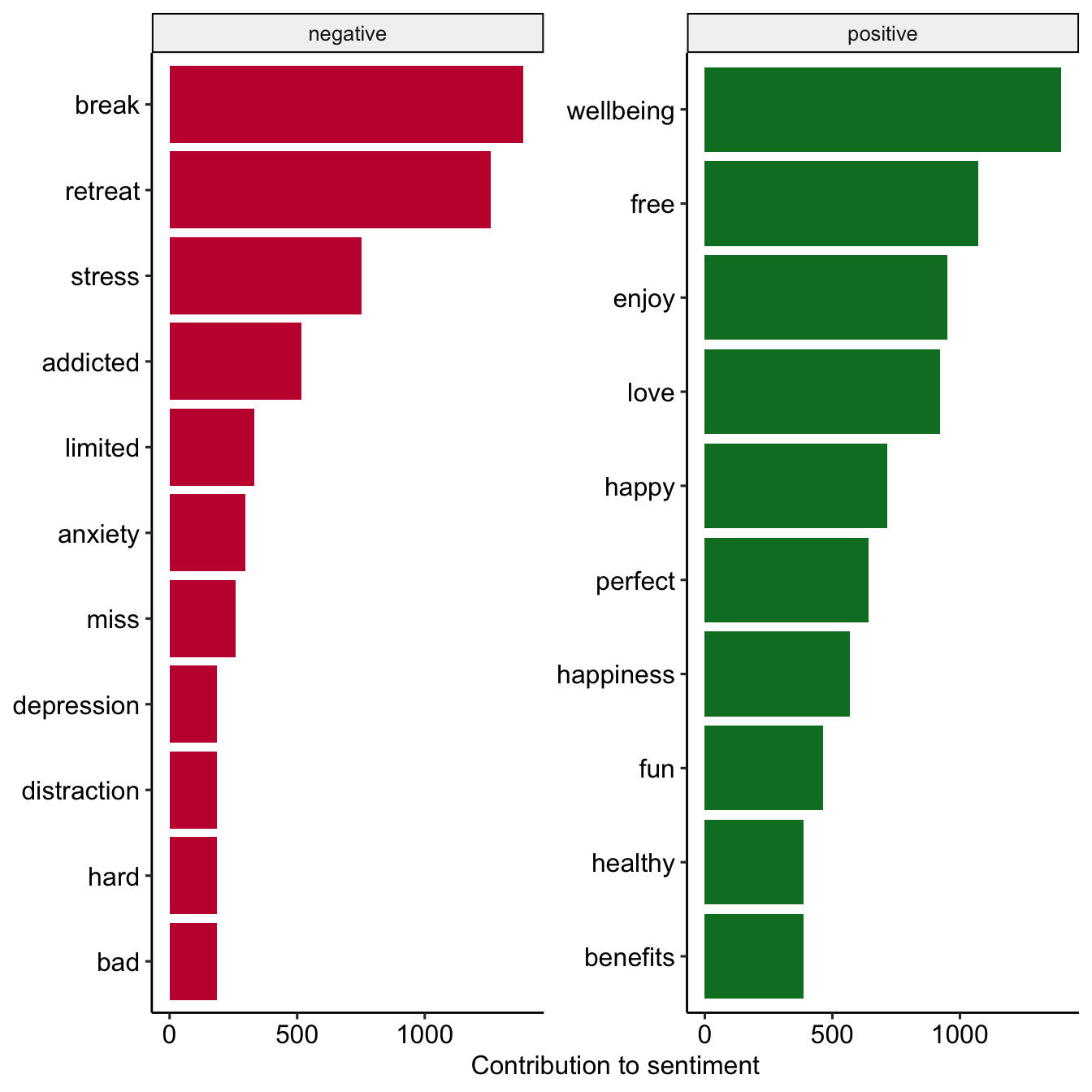
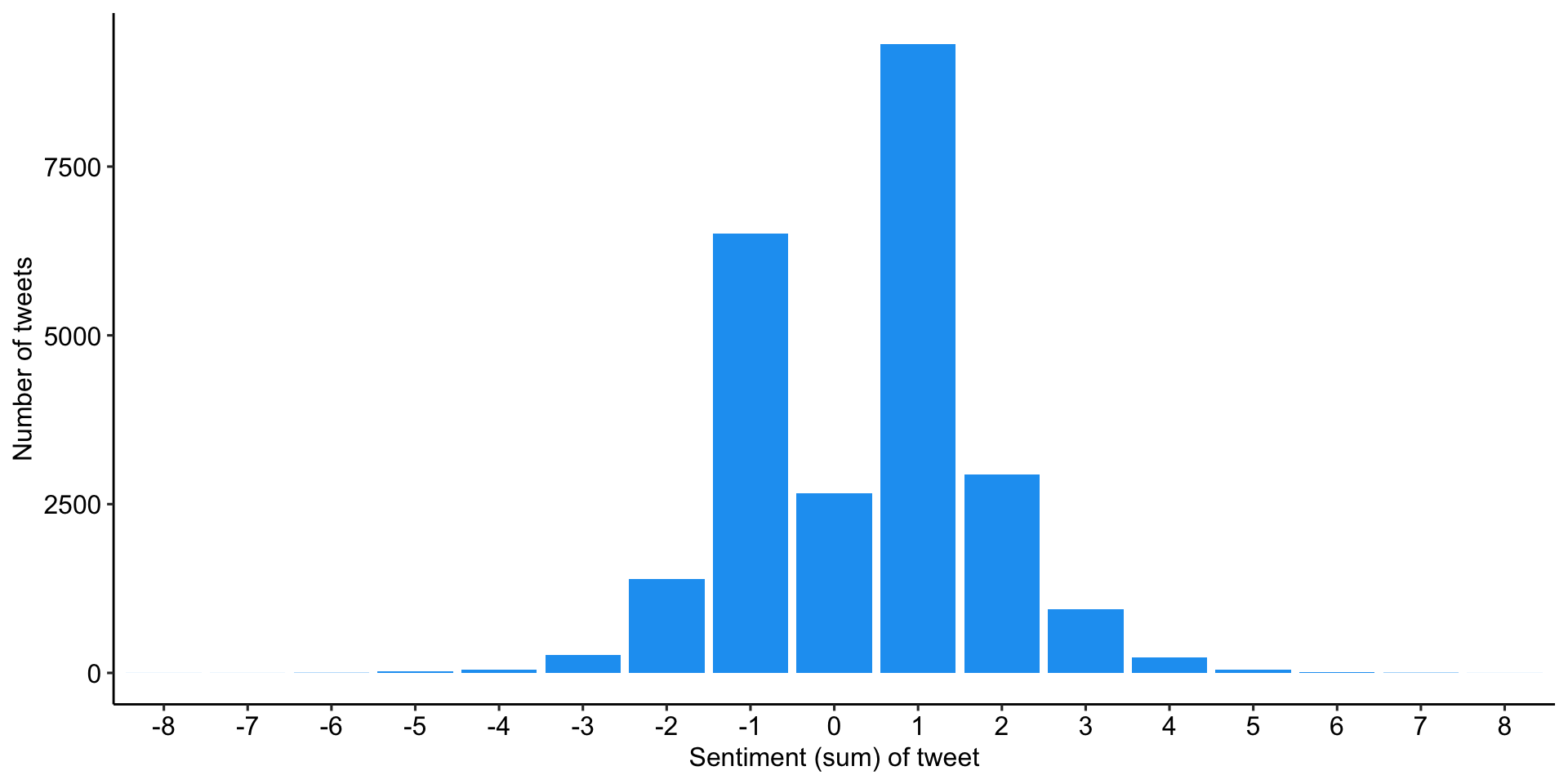
Slightly more positive tweets than negative
Overall distribution sentiment by tweets
A trend towards positivity?
Development of tweet sentiment over the years
Expand for full code
# Create first graph
g1 <- tweets_correct %>%
filter(tweet_id %in% tweets_sentiment$tweet_id) %>%
left_join(tweets_sentiment) %>%
sjmisc::rec(
sentiment,
rec = "-8:-1=negative; 0=neutral; 1:8=positive") %>%
ggplot(aes(x = as.factor(year), fill = as.factor(sentiment_r))) +
geom_bar() +
labs(
x = "",
y = "Number of tweets",
fill = "Sentiment (sum) of tweet") +
scale_fill_manual(values = c("#C50F3C", "#90A0AF", "#007D29")) +
theme_pubr()
#theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
# Create second graph
g2 <- tweets_correct %>%
filter(tweet_id %in% tweets_sentiment$tweet_id) %>%
left_join(tweets_sentiment) %>%
sjmisc::rec(
sentiment,
rec = "-8:-1=negative; 0=neutral; 1:8=positive") %>%
ggplot(aes(x = as.factor(year), fill = as.factor(sentiment_r))) +
geom_bar(position = "fill") +
labs(
x = "",
y = "Proportion of tweets",
fill = "Sentiment (sum) of tweet") +
scale_fill_manual(values = c("#C50F3C", "#90A0AF", "#007D29")) +
theme_pubr()
# COMBINE GRPAHS
ggarrange(g1, g2,
nrow = 1, ncol = 2,
align = "hv",
common.legend = TRUE) 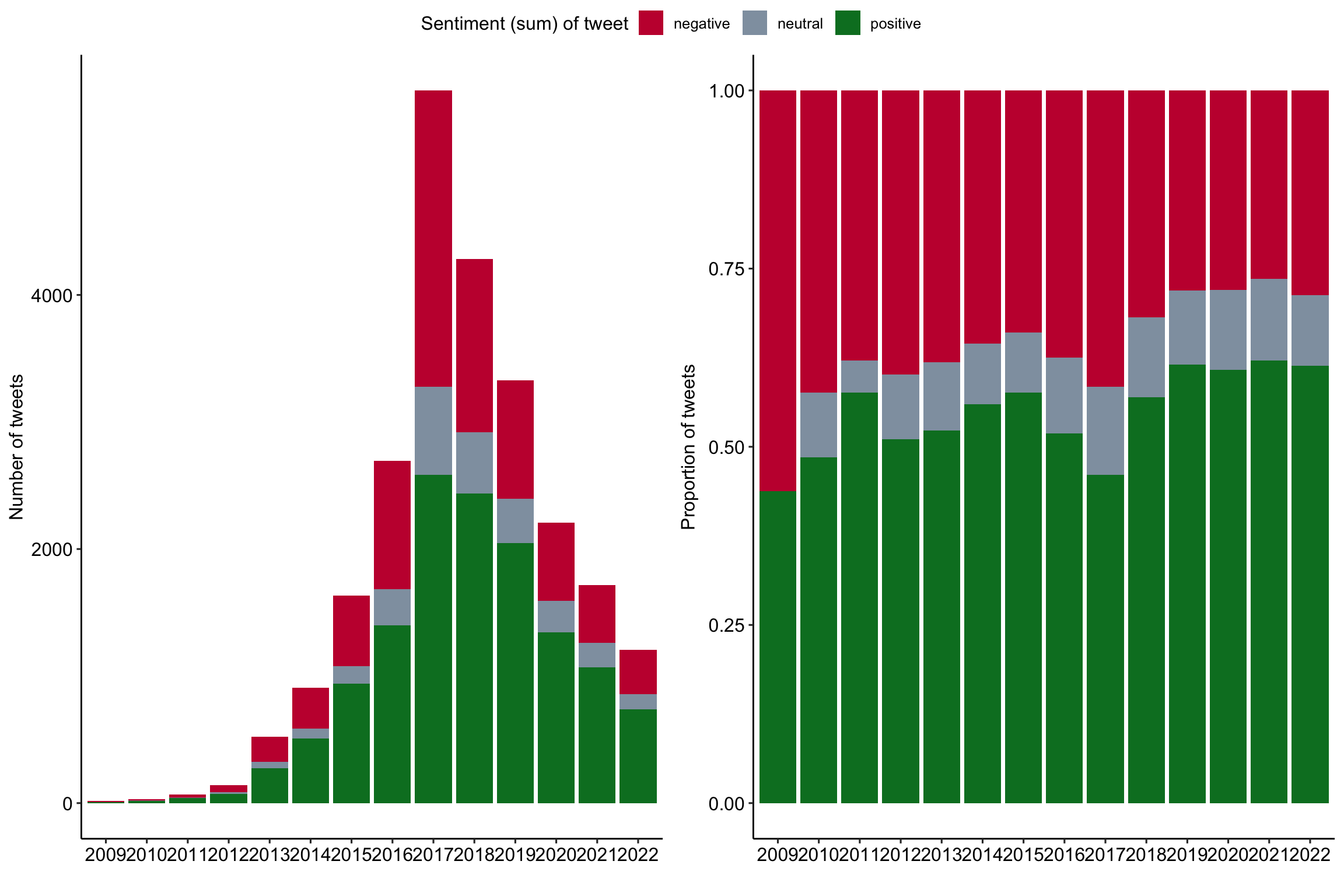
References
Atteveldt, W. van, Trilling, D., & Arcíla, C. (2021). Computational analysis of communication: A practical introduction to the analysis of texts, networks, and images with code examples in python and r. John Wiley & Sons.
Barrie, C., & Ho, J. (2021). academictwitteR: An r package to access the twitter academic research product track v2 API endpoint. Journal of Open Source Software, 6(62), 3272. https://doi.org/10.21105/joss.03272
Silge, J., & Robinson, D. (2017). Text mining with r: A tidy approach (First edition). O’Reilly.
Vanden Abeele, M. M. P., Halfmann, A., & Lee, E. W. J. (2022). Drug, demon, or donut? Theorizing the relationship between social media use, digital well-being and digital disconnection. Current Opinion in Psychology, 45, 101295. https://doi.org/10.1016/j.copsyc.2021.12.007

Social Media as 💊, 👹 or 🍩 ?
Relationship between social media use, digital well-being and digital disconnection
What is at stake?
Addiction/health
Distraction
Well-being
Root cause of problem
Individual susceptibility
Addictive design
Inadequate fit
User agency
Agency is limited due to innate susceptibilities
Agency needs to be reclaimed from social media platforms
User has agency, but it is challenged by person-, technology- and context-specific elements
Focus of disconnection
Complete abstinence, re-training of the ‘faulty brain’ to break the dopamine link
Removing/weakening the distracting potential of tech, using persuasive design to support exerting social media self-control
Disconnection interventions tailored to persons and/or contexts to ‘optimize the balance’ between benefits and drawbacks of connectivity, mindful use
Digital disconnection examples
Digital detox, cognitive behavioral therapy
Muting phone, disabling notifications, putting phone in grey-scale, using apps that reward abstinence (e.g., Forest)
Locative disconnection, disconnection apps that extensive tailoring to persons and contexts, mindfulness training
(Vanden Abeele et al., 2022)