| Session | Datum | Topic | Presenter |
|---|---|---|---|
Introduction |
|||
1 |
25.10.2023 |
Kick-Off |
Christoph Adrian |
01.11.2023 |
🎃 Holiday (No Lecture) |
||
2 |
08.11.2023 |
Einführung in DBD |
Christoph Adrian |
3 |
15.11.2023 |
🔨 Working with R |
Christoph Adrian |
🗣️ |
Presentations |
||
4 |
22.11.2023 |
📚 Media routines & habits |
Group C |
5 |
29.11.2023 |
~📚 Digital disconnection~ |
|
6 |
06.12.2023 |
📚 Digital disconnection |
Group A |
7 |
13.12.2023 |
📦 Data collection methods |
Group D |
8 |
20.12.2023 |
📦 Automatic text analysis 🎥 |
Group B |
🎄Christmas Break (No Lecture) |
|||
📂 Project |
Analysis of media content |
||
9 |
10.01.2024 |
🔨 Text as data |
Christoph Adrian |
10 |
17.01.2024 |
🔨 Automatic analysis of text in R |
Christoph Adrian |
11 |
24.01.2024 |
🔨 Q&A |
Christoph Adrian |
12 |
31.01.2024 |
📊 Presentation & Discussion |
All groups |
13 |
07.02.2024 |
🏁 Recap, Evaluation & Discussion |
Christoph Adrian |
🔨 Automatic text analysis in R
Session 10
17.01.2024
The tidy text format pipeline basics
Focus on single words and their relationship documents & sentiments

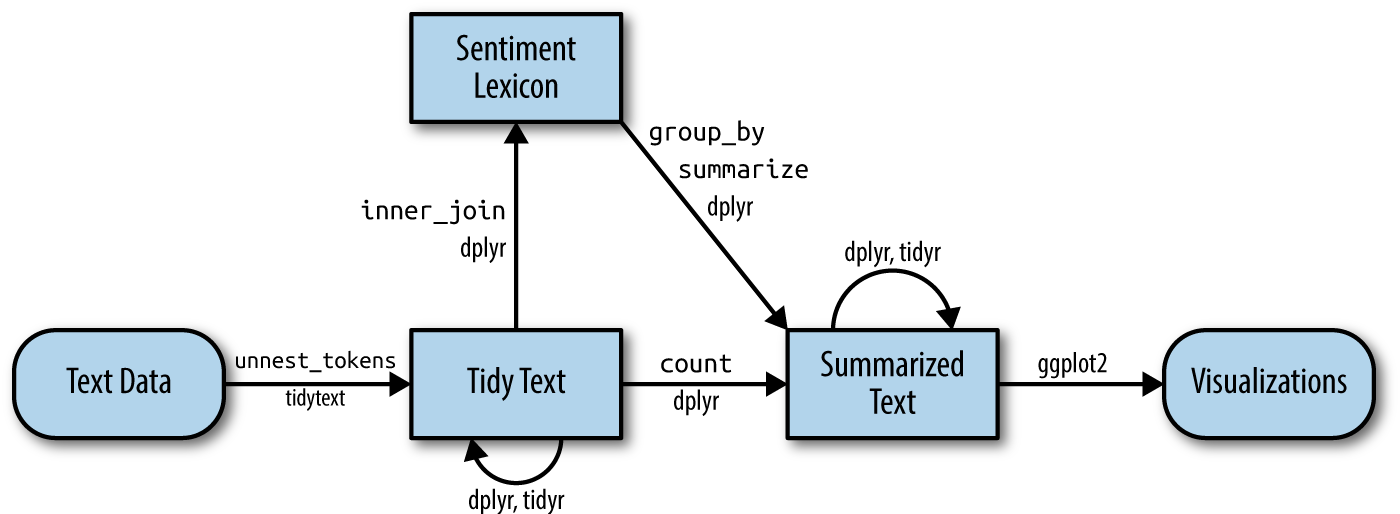
Silge & Robinson (2017)
Expansion of the pipeline
Focus on modeling the realtionships between words & documents
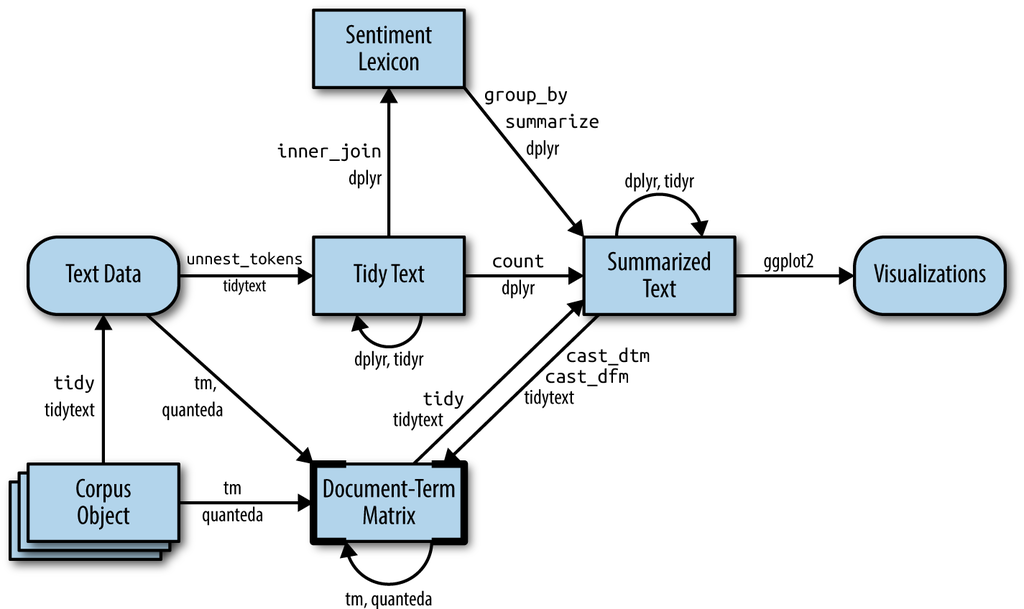
Silge & Robinson (2017)
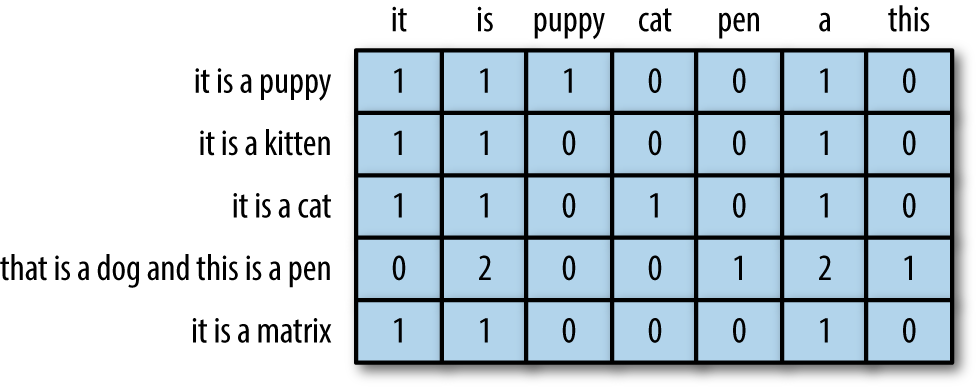
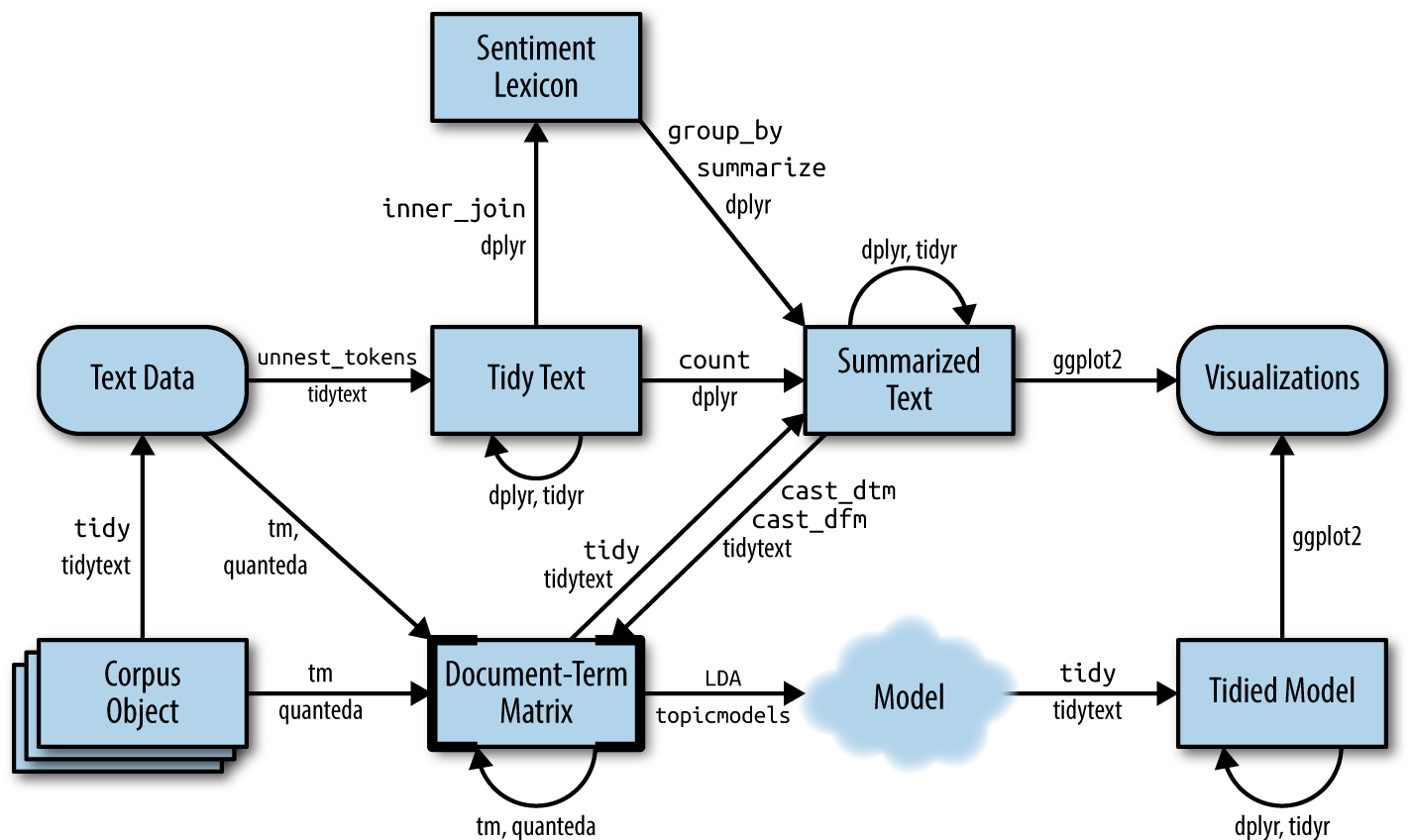
Quick recap on Document-Term Matrix [DTM]
Most common structure for (classic) text mining
A matrix where:
each row represents one document (such as a tweet),
each column represents one term, and
each value (typically) contains the number of appearances of that term in that document.
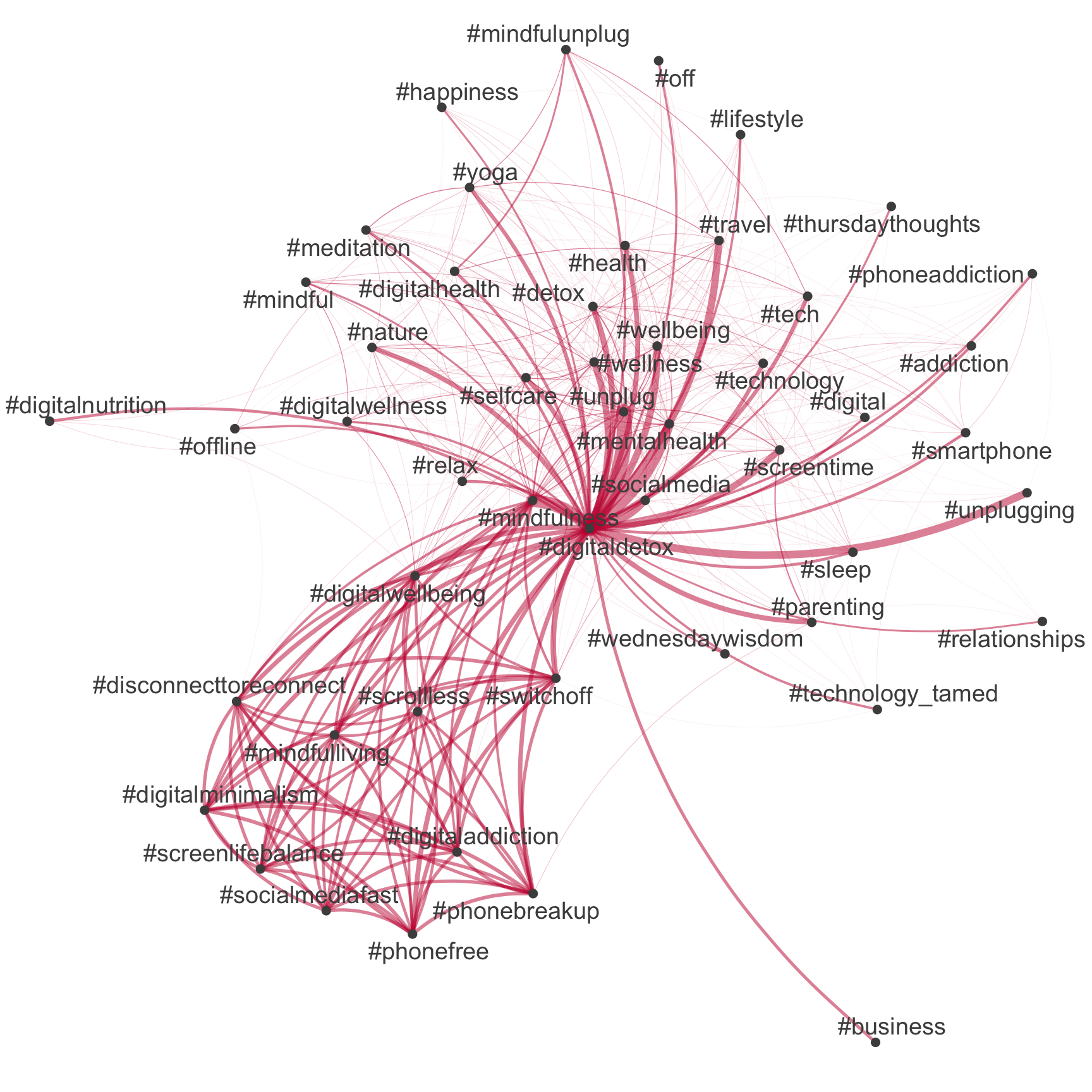
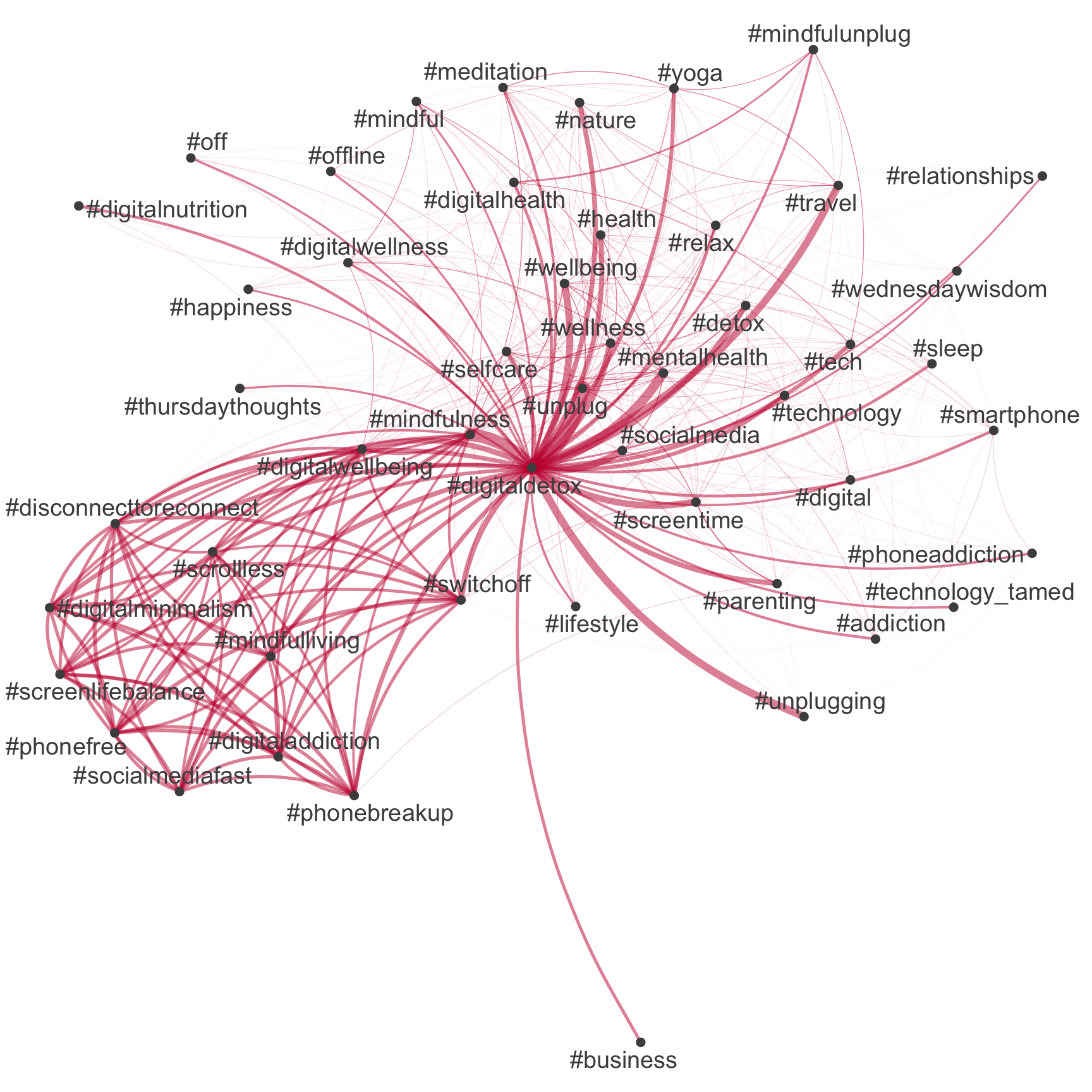
An example: Network of hashtags
Comparison between tidytext & quanteda
# Extract hashtags
tweets_hashtags <- tweets_detox %>%
mutate(hashtags = str_extract_all(
text, "#\\S+")) %>%
unnest(hashtags)
# Extract most common hashtags
top50_hashtags_tidy <- tweets_hashtags %>%
count(hashtags, sort = TRUE) %>%
slice_head(n = 50) %>%
pull(hashtags)
# Visualize
tweets_hashtags %>%
count(tweet_id, hashtags, sort = TRUE) %>%
cast_dfm(tweet_id, hashtags, n) %>%
quanteda::fcm() %>%
quanteda::fcm_select(
pattern = top50_hashtags_tidy,
case_insensitive = FALSE
) %>%
quanteda.textplots::textplot_network(
edge_color = "#04316A"
)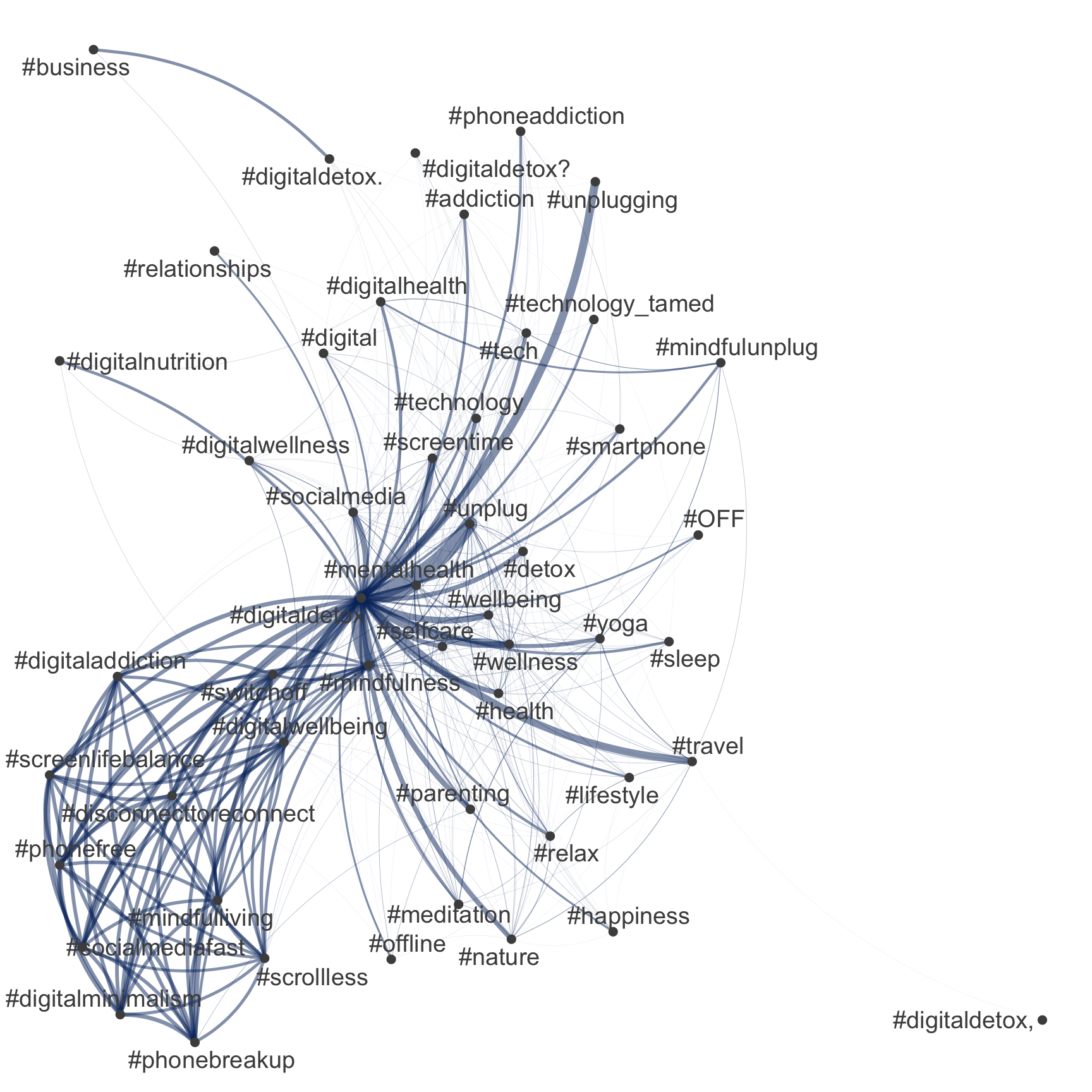
An example: Network of hashtags
Comparison between tidytext & quanteda
# Extract DFM with only hashtags
quanteda_dfm_hashtags <- quanteda_dfm %>%
quanteda::dfm_select(pattern = "#*")
# Extract most common hashtags
top50_hashtags_quanteda <- quanteda_dfm_hashtags %>%
topfeatures(50) %>%
names()
# Construct feature-occurrence matrix of hashtags
quanteda_dfm_hashtags %>%
fcm() %>%
fcm_select(pattern = top50_hashtags_quanteda) %>%
textplot_network(
edge_color = "#C50F3C"
) 
An example: Network of hashtags
Comparison between tidytext & quanteda
A new input in the pipeline
Unsupervised learning example: Topic modeling
Silge & Robinson (2017)
Semantic coherence as the key
Different model statistics for evaluation
Expand for full code
stm_results %>%
transmute(
k,
`Lower bound` = lbound,
Residuals = map_dbl(residual, "dispersion"),
`Semantic coherence` = map_dbl(semantic_coherence, mean),
`Held-out likelihood` = map_dbl(eval_heldout, "expected.heldout")) %>%
gather(Metric, Value, -k) %>%
ggplot(aes(k, Value, color = Metric)) +
geom_line(size = 1.5, alpha = 0.7, show.legend = FALSE) +
geom_point(size = 3) +
scale_x_continuous(breaks = seq(from = 5, to = 85, by = 5)) +
facet_wrap(~Metric, scales = "free_y") +
labs(x = "K (number of topics)",
y = NULL,
title = "Model diagnostics by number of topics"
) +
theme_pubr() +
# add highlights
geom_vline(aes(xintercept = 5), color = "#00BFC4", alpha = .5) +
geom_vline(aes(xintercept = 10), color = "#C77CFF", alpha = .5) +
geom_vline(aes(xintercept = 40), color = "#C77CFF", alpha = .5) 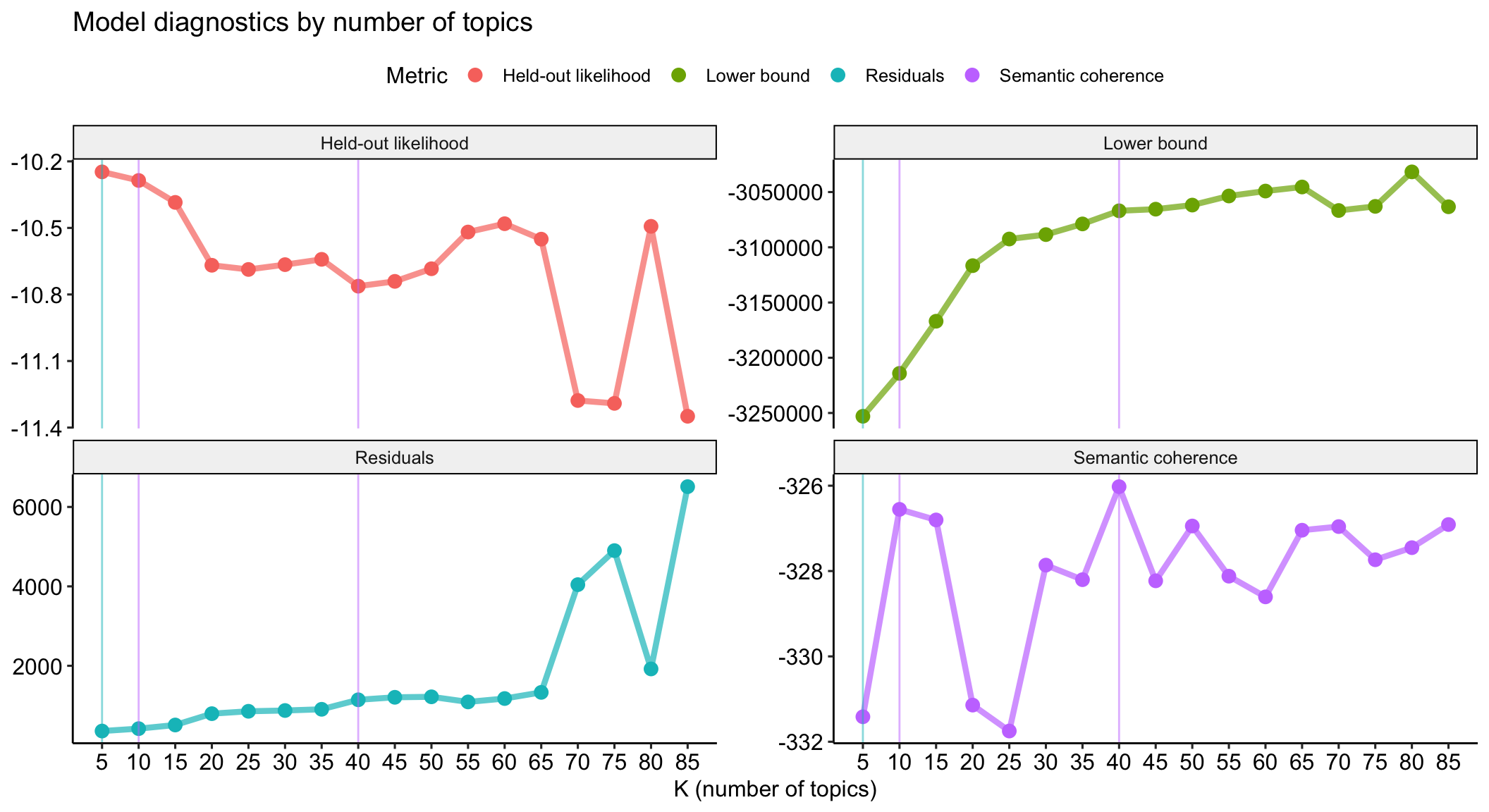
Finding the best trade-off
Comparison of selected models based on exclusivty and semantic coherence
Expand for full code
# Models for comparison
models_for_comparison = c(5, 10, 40)
# Create figures
stm_results %>%
# Edit data
select(k, exclusivity, semantic_coherence) %>%
filter(k %in% models_for_comparison) %>%
unnest(cols = c(exclusivity, semantic_coherence)) %>%
mutate(k = as.factor(k)) %>%
# Build graph
ggplot(aes(semantic_coherence, exclusivity, color = k)) +
geom_point(size = 2, alpha = 0.7) +
labs(
x = "Semantic coherence",
y = "Exclusivity"
# title = "Comparing exclusivity and semantic coherence",
# subtitle = "Models with fewer topics have higher semantic coherence for more topics, but lower exclusivity"
) +
theme_pubr() 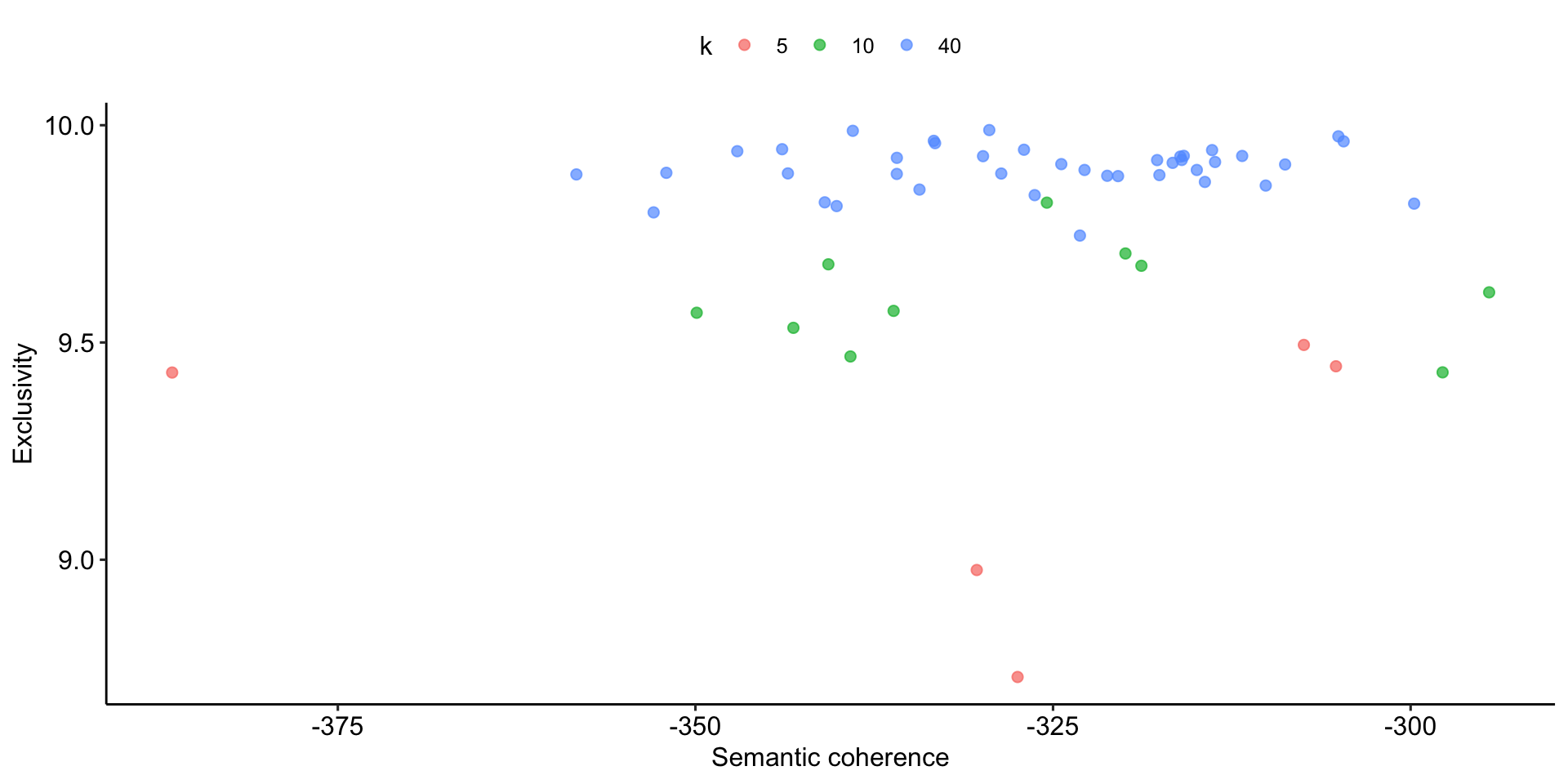
A first overview
Understanding the ‘final’ model (k = 10)
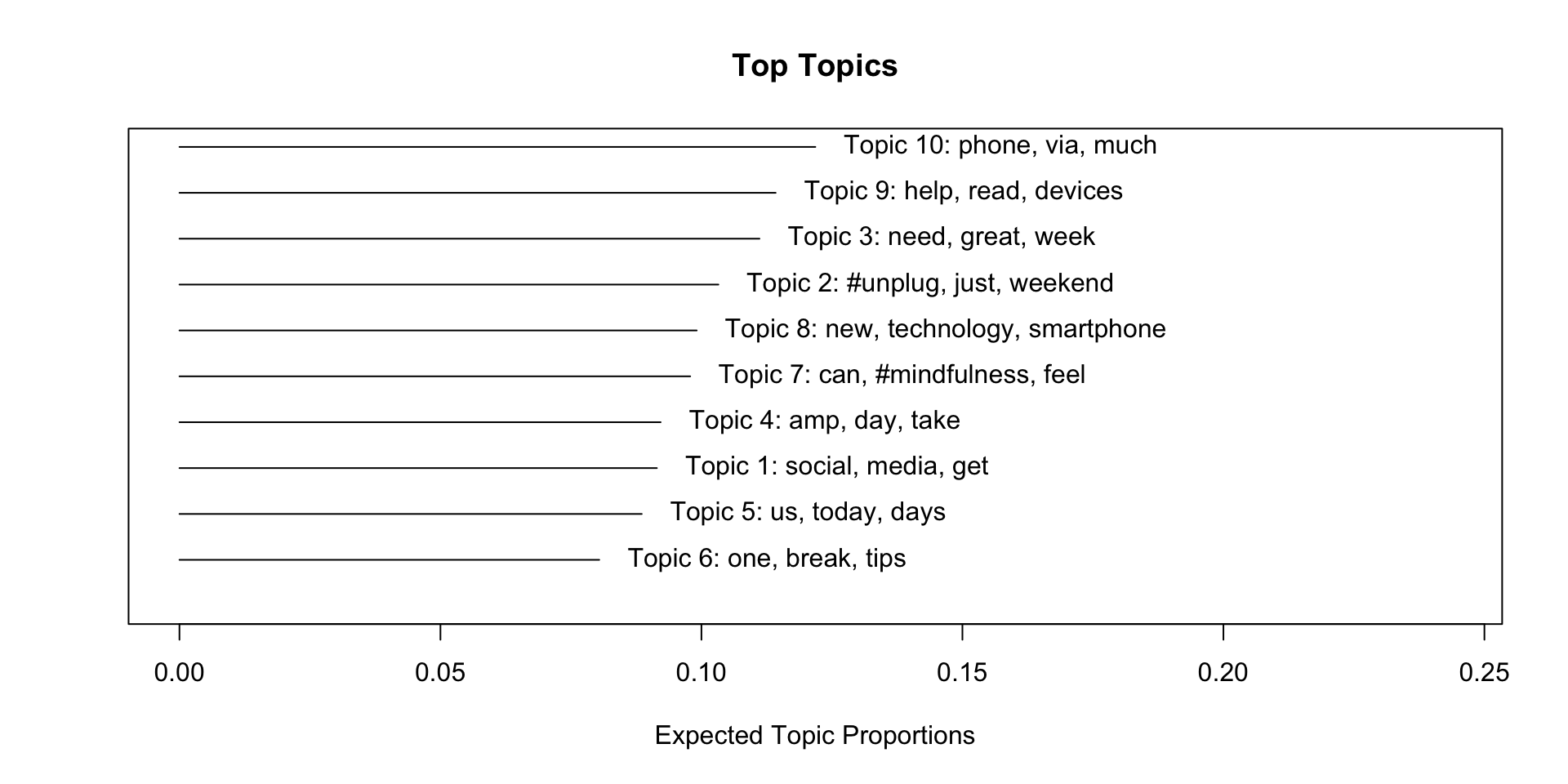
Results in a different context
Merge back with original data for further analysis and comparison
top_gamma %>%
ggplot(aes(as.factor(topic), gamma)) +
geom_col(fill = "#F57350") +
labs(
x = "Topic",
y = "Mean gamma"
) +
coord_flip() +
scale_y_reverse() +
scale_x_discrete(position = "top") +
theme_pubr()
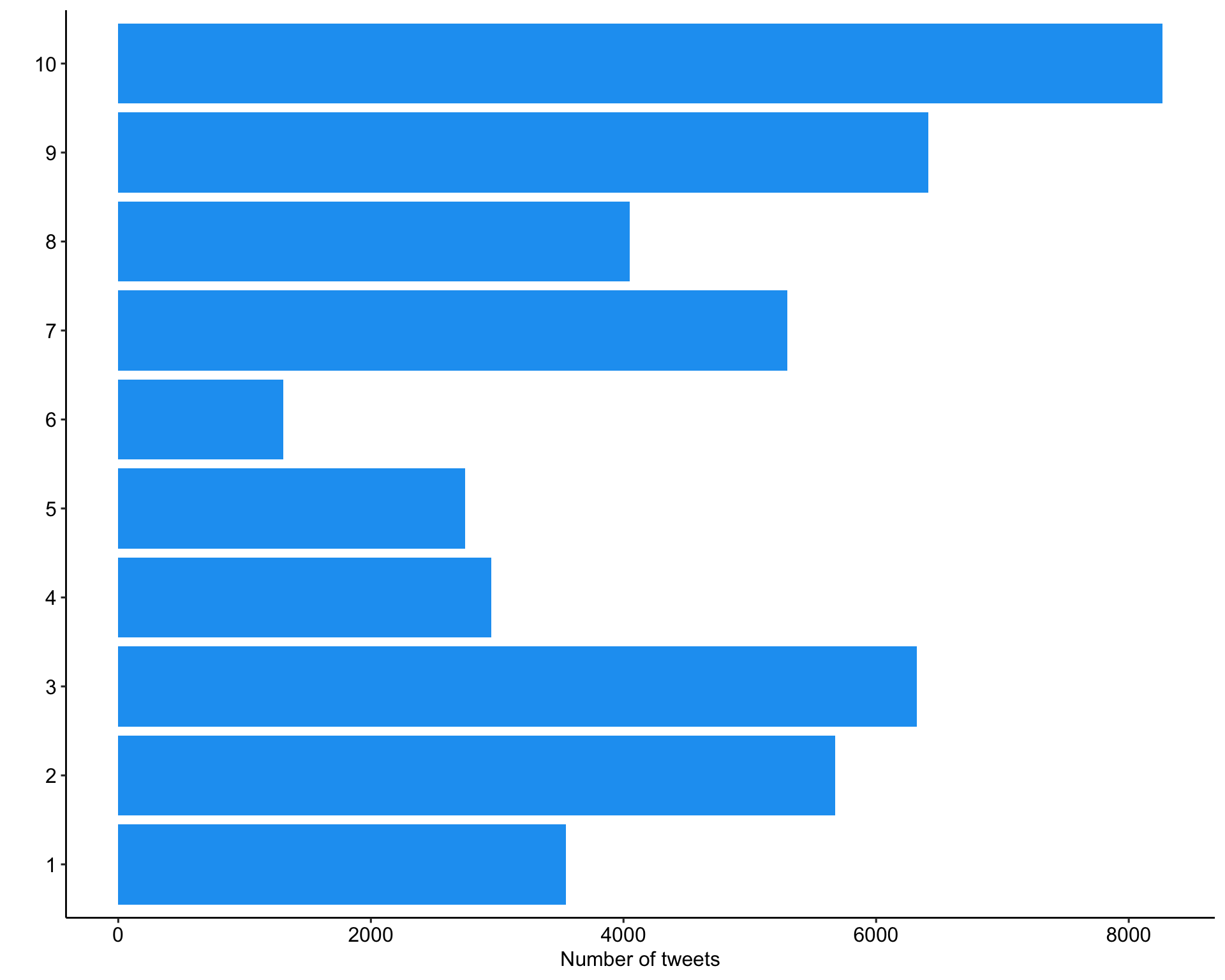
tweets_detox_topics %>%
mutate(across(top_topic, as.factor)) %>%
ggplot(aes(top_topic)) +
geom_bar(fill = "#1DA1F2") +
labs(
x = "",
y = "Number of tweets"
) +
coord_flip() +
theme_pubr()Expand for full code
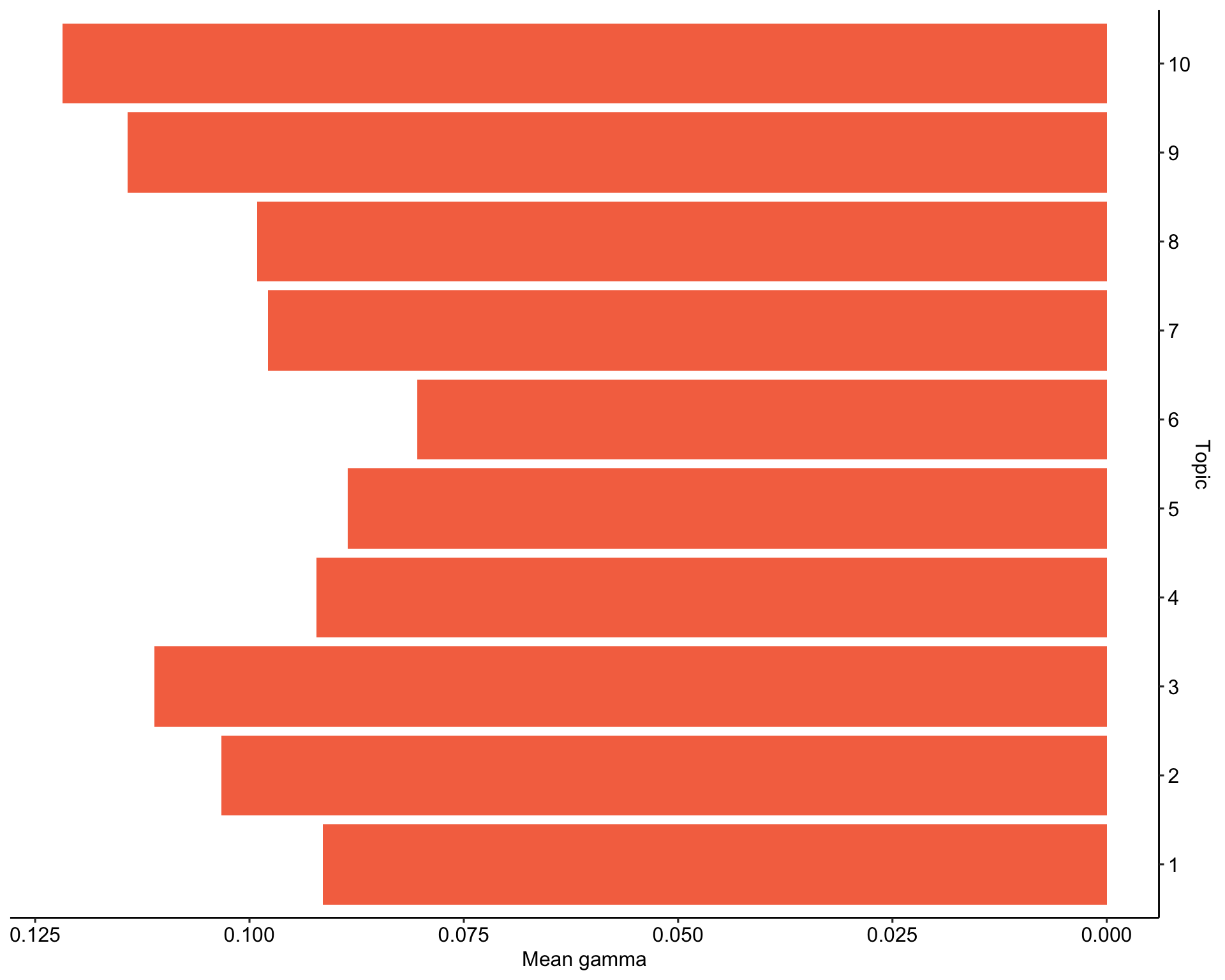
Expand for full code
References
Barrie, C., & Ho, J. (2021). academictwitteR: An r package to access the twitter academic research product track v2 API endpoint. Journal of Open Source Software, 6(62), 3272. https://doi.org/10.21105/joss.03272
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. The Journal of Machine Learning Research, 3, 9931022.
Chan, C., & Sältzer, M. (2020). Oolong: An r package for validating automated content analysis tools. Journal of Open Source Software, 5(55), 2461. https://doi.org/10.21105/joss.02461
Chang, J., Boyd-Graber, J., Gerrish, S., Wang, C., & Blei, D. (2009). Reading tea leaves: How humans interpret topic models. 32, 288–296.
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding (J. Burstein, C. Doran, & T. Solorio, Eds.; p. 41714186). Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1423
Le, Q., & Mikolov, T. (2014). Distributed representations of sentences and documents (E. P. Xing & T. Jebara, Eds.; Vol. 32, p. 11881196). PMLR. https://proceedings.mlr.press/v32/le14.html
Maier, D., Waldherr, A., Miltner, P., Wiedemann, G., Niekler, A., Keinert, A., Pfetsch, B., Heyer, G., Reber, U., Häussler, T., Schmid-Petri, H., & Adam, S. (2018). Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology. Communication Methods and Measures, 12(2-3), 93–118. https://doi.org/10.1080/19312458.2018.1430754
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality (C. J. Burges, L. Bottou, M. Welling, Z. Ghahramani, & K. Q. Weinberger, Eds.; Vol. 26). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global vectors for word representation. 15321543. https://doi.org/10.3115/v1/D14-1162
Roberts, M. E., Stewart, B. M., & Airoldi, E. M. (2016). A model of text for experimentation in the social sciences. Journal of the American Statistical Association, 111(515), 988–1003. https://doi.org/f88tzh
Roberts, M. E., Stewart, B. M., & Tingley, D. (2019). stm: An R Package for Structural Topic Models. Journal of Statistical Software, 91(1), 1–40. https://doi.org/10.18637/jss.v091.i02
Silge, J., & Robinson, D. (2017). Text mining with r: A tidy approach (First edition). O’Reilly.
Zheng, A., & Casari, A. (2018). Feature engineering for machine learning: Principles and techniques for data scientists (First edition). O’Reilly.

Social Media as 💊, 👹 or 🍩 ?
Discussion about digital disconnection on twitter
Increasing trend towards more conscious use of digital media (devices), including (deliberate) non-use with the aim to restore or improve psychological well-being (among other factors)
Collect all tweets (until 31.12.2022) via Twitter Academic Research Product Track v2 API &
academictwitteRpackage (Barrie & Ho, 2021) that mention or discuss digital detox (and similar terms)Dataset for session is a subsample (n = 46670) with only tweets that contain
#digitaldetox.