if (!require("pacman")) install.packages("pacman")
pacman::p_load(
here, qs, # file management
magrittr, janitor, # data wrangling
easystats, sjmisc, # data analysis
gt, gtExtras, # table visualization
ggpubr, ggwordcloud, # visualization
# text analysis
tidytext, widyr, # based on tidytext
quanteda, # based on quanteda
quanteda.textmodels, quanteda.textplots, quanteda.textstats,
openalexR,
tidyverse # load last to avoid masking issues
)Unsupervised Machine Learning I
Session 09 - Exercise
![]() Link to source file
Link to source file
Ziel der Anwendung: Textanalyse in R kennenlernen
- Typische Schritte der Textanalyse mit
quantedakennenlernen, von der Tokenisierung bis zur Visualisierung.
Background
Todays’s data basis: OpenAlex
Via API bzw. openalexR (Aria et al. 2024) gesammelte “works” der Datenbank OpenAlex mit Bezug zu Literaturriews in den Sozialwissenschaften zwischen 2013 und 2023
Detaillierte Informationen und Ergebnisse zur Suchquery finden Sie hier.
Preparation
Wichtige Information
- Bitte stellen Sie sicher, dass Sie das jeweilige R-Studio Projekt zur Übung geöffnet haben. Nur so funktionieren alle Dependencies korrekt.
- Um den einwandfreien Ablauf der Übung zu gewährleisten, wird für die Aufgaben auf eine eigenständige Datenerhebung verzichtet und ein Übungsdatensatz zu verfügung gestelt.
Packages
Import und Vorverarbeitung der Daten
# Import from local
review_works <- qs::qread(here("data/session-07/openalex-review_works-2013_2023.qs"))
# Create correct data
review_works_correct <- review_works %>%
mutate(
# Create additional factor variables
publication_year_fct = as.factor(publication_year),
type_fct = as.factor(type)
)
# Create subsample
review_subsample <- review_works_correct %>%
# Eingrenzung: Sprache und Typ
filter(language == "en") %>%
filter(type == "article") %>%
# Eingrenzung: Keine Einträge ohne Abstract
filter(!is.na(ab)) %>%
# Datentranformation
unnest(topics, names_sep = "_") %>%
filter(topics_name == "field" ) %>%
filter(topics_i == "1") %>%
# Eingrenzung: Forschungsfeldes
filter(
topics_display_name == "Social Sciences"|
topics_display_name == "Psychology"
) %>%
# Eingrenzung: Keine Einträge ohne Abstract
filter(!is.na(ab)) Erstellung Korpus & DFM
Lösung anzeigen
# Create corpus
quanteda_corpus <- review_subsample %>%
quanteda::corpus(
docid_field = "id",
text_field = "ab"
)
# Tokenize
quanteda_token <- quanteda_corpus %>%
quanteda::tokens(
remove_punct = TRUE,
remove_symbols = TRUE,
remove_numbers = TRUE,
remove_url = TRUE,
split_tags = FALSE # keep hashtags and mentions
) %>%
quanteda::tokens_tolower() %>%
quanteda::tokens_remove(
pattern = stopwords("en")
)
# Convert to Document-Feature-Matrix (DFM)
quanteda_dfm <- quanteda_token %>%
quanteda::dfm()🛠️ Praktische Anwendung
Achtung, bitte lesen!
- Bevor Sie mit der Arbeit an den folgenden 📋 Exercises beginnen, stellen Sie bitte sicher, dass Sie alle Chunks des Abschnitts Preparation gerendert haben. Das können Sie tun, indem Sie den “Run all chunks above”-Knopf
 des nächsten Chunks benutzen.
des nächsten Chunks benutzen. - Bei Fragen zum Code lohnt sich ein Blick in den Showcase (.qmd oder .html). Beim Showcase handelt es sich um eine kompakte Darstellung des in der Präsentation verwenden R-Codes. Sie können das Showcase also nutzen, um sich die Code-Bausteine anzusehen, die für die R-Outputs auf den Slides benutzt wurden.
📋 Exercise 1: Cleaned DFM
- Erstelen Sie einen neuen Datensatz
quanteda_dfm_cleaned- basierend auf dem Datensatz
quanteda_dfm- Verwenden Sie
quanteda::dfm_remove(pattern = c("systematic", "literature", "review"), um die Suchquery zu entfernen. - Speichern Sie diese Umwandlung, indem Sie einen neuen Datensatz mit dem Namen
quanteda_dfm_cleanederstellen.
- Verwenden Sie
- basierend auf dem Datensatz
- Überprüfen Sie die Transformation indem Sie
quanteda_dfm_cleanedin die Konsole eingeben. - ✍️ Notieren Sie, wie viele Dokumente & Features in
quanteda_dfm_cleanedenthalten sind.
Lösung anzeigen
# `quanteda_dfm_cleaned` erstellen
quanteda_dfm_cleaned <- quanteda_dfm %>%
quanteda::dfm_remove(pattern = c("systematic", "literature", "review"))
# Überprüfung
quanteda_dfm_cleanedDocument-feature matrix of: 36,680 documents, 135,074 features (99.93% sparse) and 43 docvars.
features
docs 5-item world health organization well-being
https://openalex.org/W4293003987 1 2 1 1 3
https://openalex.org/W2750168540 0 0 0 0 0
https://openalex.org/W1998933811 0 0 0 0 0
https://openalex.org/W2547134104 0 0 7 0 4
https://openalex.org/W3047898105 0 0 4 0 0
https://openalex.org/W2149640470 0 0 0 0 0
features
docs index who-5 among widely used
https://openalex.org/W4293003987 1 10 1 1 3
https://openalex.org/W2750168540 0 0 0 0 0
https://openalex.org/W1998933811 0 0 0 0 0
https://openalex.org/W2547134104 0 0 0 0 1
https://openalex.org/W3047898105 0 0 0 0 0
https://openalex.org/W2149640470 0 0 0 0 1
[ reached max_ndoc ... 36,674 more documents, reached max_nfeat ... 135,064 more features ]Lösung anzeigen
# Notiz:
# `quanteda_dfm_cleaned` enthält 36680 Dokumente und 135074 Features.📋 Exercise 2: Neues Netzwerk der Top-Begriffe
- Neues Dataset
top_features_quantedaerstellen- Basierend auf dem Dataset
quanteda_dfm_cleaned, - Verwenden Sie
quanteda::topfeatures(20), um die 20 häufigsten Begriffe zu extrahieren. - Verwenden Sie
names(), um nur die Namen (nicht die Werte) zu speichern. - Speichern Sie diese Transformation, indem Sie einen neuen Datensatz mit dem Namen
top_features_quantedaerstellen.
- Basierend auf dem Dataset
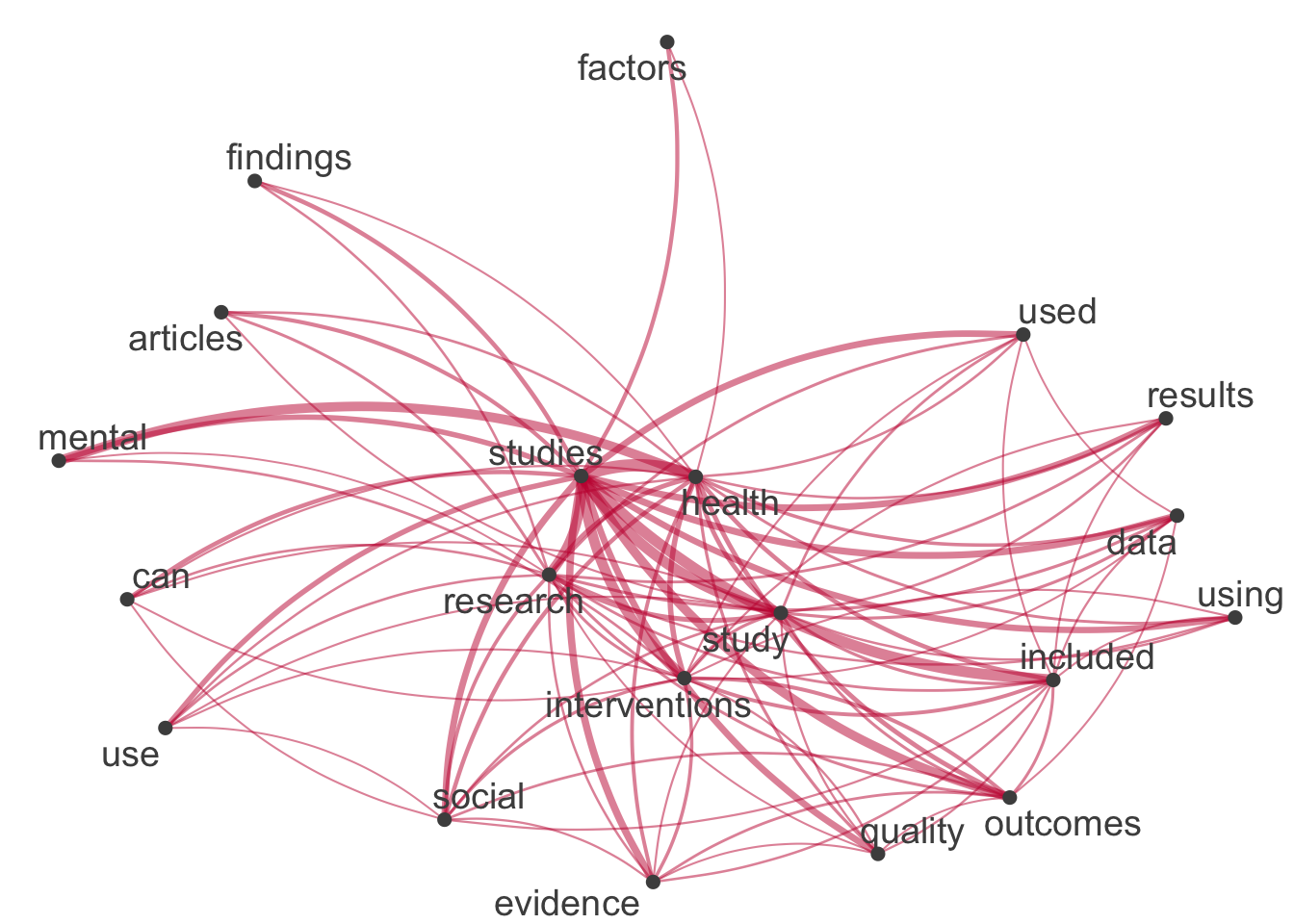
- Visualisierung des Netzwerks an Top-Begriffen
- Basierend auf dem Dataset quanteda_dfm_cleaned,
- Transformieren Sie die Daten mit
quanteda::fcm()in eine Feature-Co-Occurrence-Matrix [FCM]. - Auswahl relevanter Hashtags mit
quanteda::fcm_select(pattern = top_features_quanteda, case_insensitive = FALSE). - Visualisierung mit
quanteda.textplots::textplot_network().
- Ergebnisse interpretieren und vergleichen
- Analysieren Sie die Beziehungen zwischen den Top-Begriffen.
- Vergleichen Sie die Ergebnisse mit den Auswertungen der Folien. Welche Unterschiede gibt es?
Lösung anzeigen
# Create top features
top_features_quanteda <- quanteda_dfm_cleaned %>%
topfeatures(20) %>%
names()
# Construct feature-occurrence matrix of features
quanteda_dfm_cleaned %>%
fcm() %>%
fcm_select(pattern = top_features_quanteda) %>%
textplot_network(
edge_color = "#C50F3C"
) 
References
Aria, Massimo, Trang Le, Corrado Cuccurullo, Alessandra Belfiore, and June Choe. 2024. “openalexR: An R-Tool for Collecting Bibliometric Data from OpenAlex.” The R Journal 15 (4): 167–80. https://doi.org/10.32614/rj-2023-089.