| Sitzung | Datum | Thema (synchron) | Übung (asynchron) | Dozent:in |
|---|---|---|---|---|
| 1 | 18.04.2024 | Einführung & Überblick | R-Einführung | AM & CA |
| 2 | 📚 | Teil 1: Systematic Review | R-Einführung | AM |
| 3 | 25.04.2024 | Einführung in Systematic Reviews I | R-Einführung | AM |
| 4 | 02.05.2024 | Einführung in Systematic Reviews II | R-Einführung | AM |
| 5 | 09.05.2024 | 🏖️ Feiertag | R-Einführung | ED |
| 6 | 16.05.2024 | Automatisierung von SRs & KI-Tools | R-Einführung | AM |
| 7 | 23.05.2024 | 🍻 WiSo-Projekt-Woche | R-Einführung | CA |
| 8 | 04.06.2024 | 🍕 Gastvortrag: Prof. Dr. Emese Domahidi | zur Sitzung | CA |
| 9 | 06.06.2024 | Automatisierung von SRs & KI-Tools | zur Sitzung | CA |
| 10 | 💻 | Teil 2: Text as Data & Unsupervised Machine Learning | zur Sitzung | CA & AM |
| 11 | 13.06.2024 | Introduction to Text as Data | zur Sitzung | CA & AM |
| 12 | 20.06.2024 | Text processing | zur Sitzung | CA & AM |
| 1 | 27.06.2024 | Unsupervised Machine Learning I | zur Sitzung | AM & CA |
| 2 | 04.07.2024 | Unsupervised Machine Learning II | R-Einführung | AM |
| 3 | 11.07.2024 | Recap & Ausblick | R-Einführung | AM |
| 4 | 18.07.2024 | 🏁 Semesterabschluss | R-Einführung | AM |
Text processing
Sitzung 08
20.06.2024
Building a shared vocabulary
Wichtige Begriffe und Konzepte

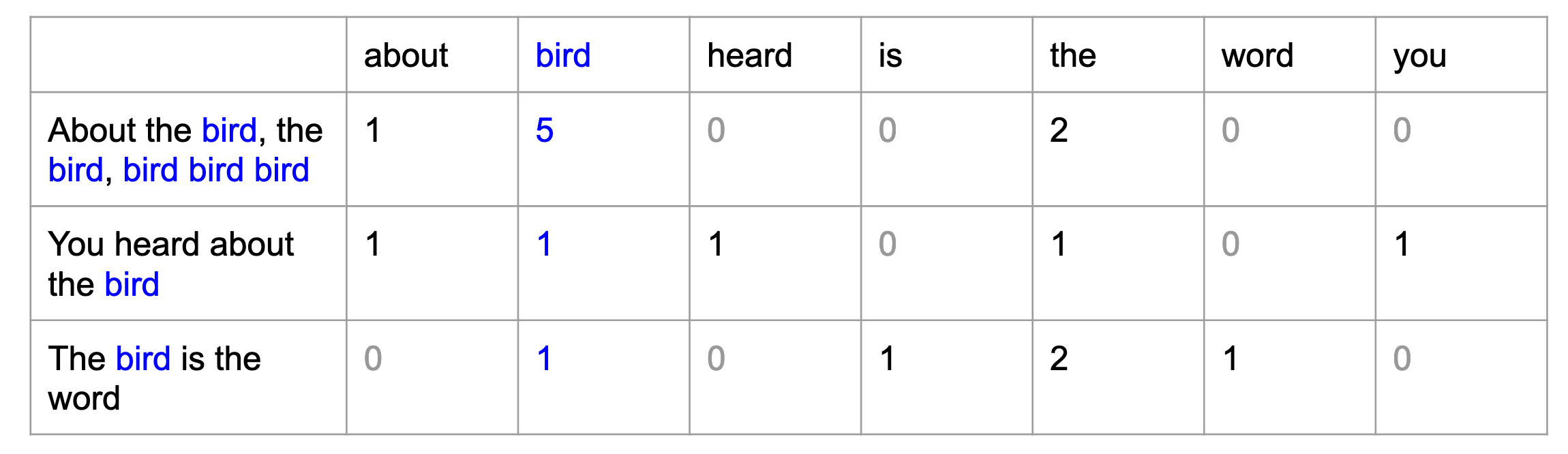
A “bag of words”
Einfache Technik im Natural Language Processing (NLP)
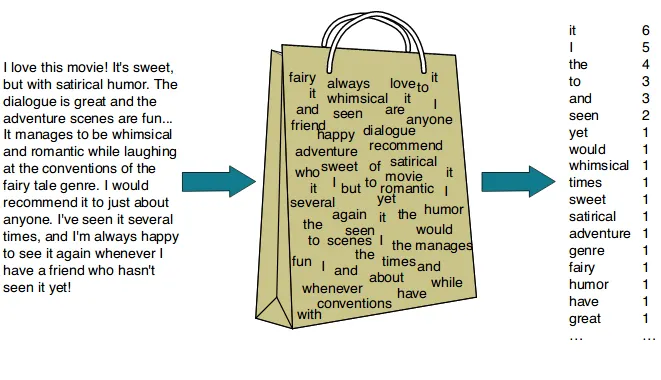
- a collection of words, disregarding grammar, word order, and context.
Vom Korpus zum Token
Einfaches Beispiel zur Darstellung der verschiedenen Konzepte
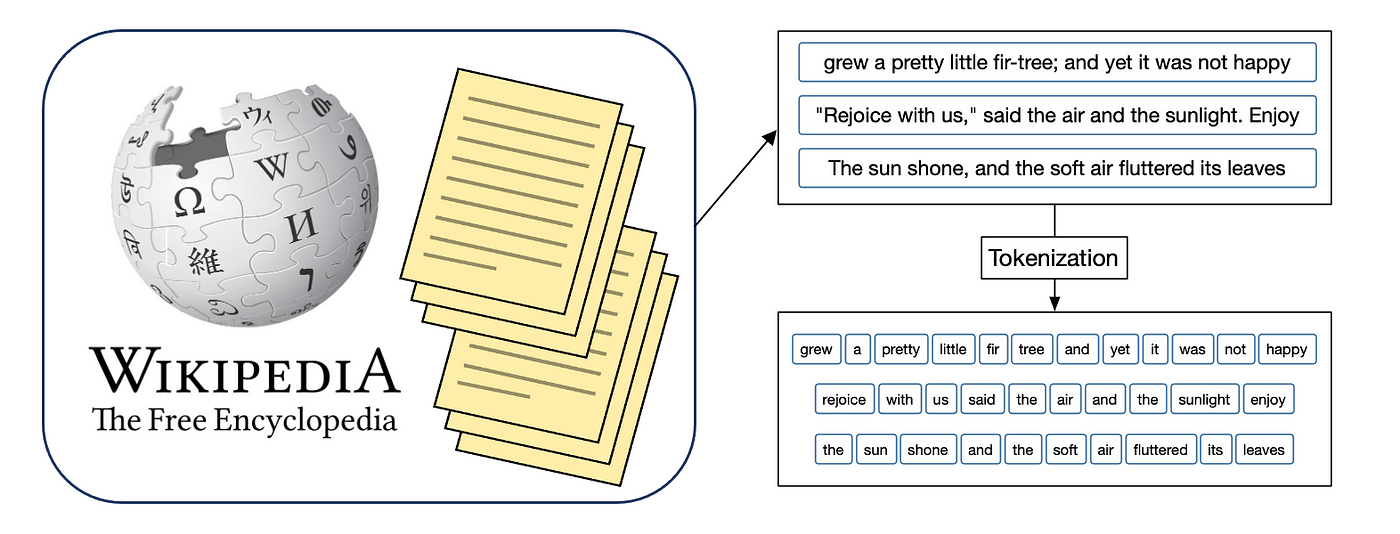
Vom Korpus zum Token zum Model
Komplexer Prozess der Textverarbeitung
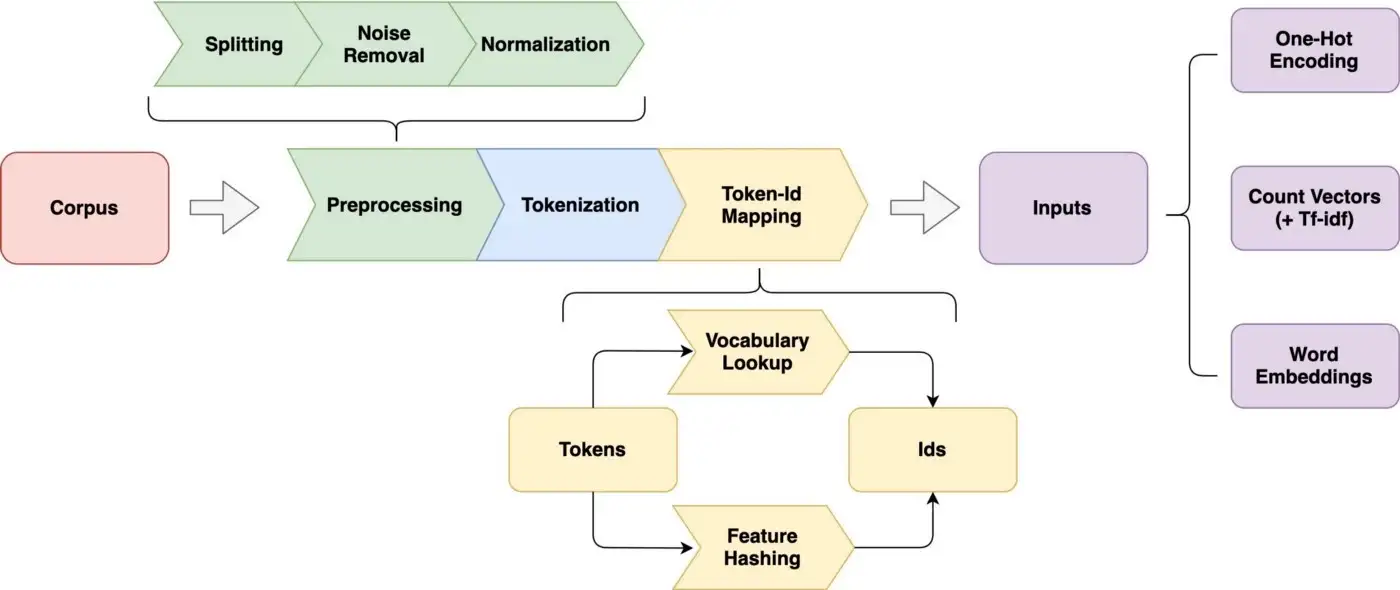
by Jiawei Hu
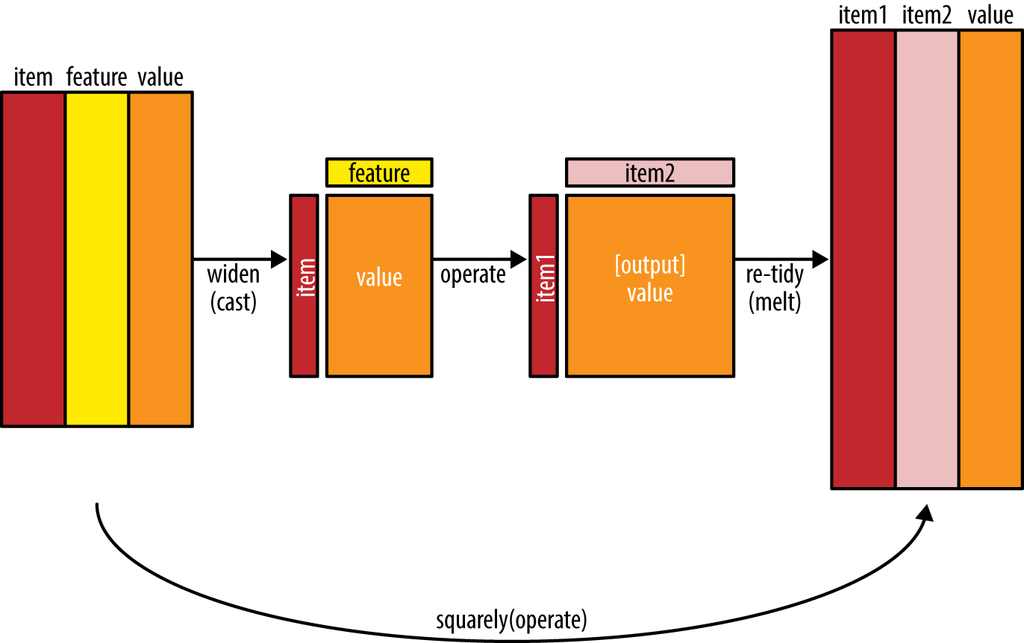
Von BoW zu DFM
Transformation des Bag-of-Words (BOW) zur Document-Feature-Matrix (DFM)
Build the subsample
Fokus auf englische Artikel aus den Sozialwissenschaften und der Psychologie
review_subsample <- review_works_correct %>%
# Eingrenzung: Sprache und Typ
filter(language == "en") %>%
filter(type == "article") %>%
# Datentranformation
unnest(topics, names_sep = "_") %>%
filter(topics_name == "field") %>%
filter(topics_i == "1") %>%
# Eingrenzung: Forschungsfeldes
filter(
topics_display_name == "Social Sciences"|
topics_display_name == "Psychology"
)Expand for full code
review_works_correct %>%
mutate(
included = ifelse(id %in% review_subsample$id, "Ja", "Nein"),
included = factor(included, levels = c("Nein", "Ja"))
) %>%
ggplot(aes(x = publication_year_fct, fill = included)) +
geom_bar() +
labs(
x = "",
y = "Anzahl der Einträge",
fill = "In Subsample enthalten?"
) +
scale_fill_manual(values = c("#A0ACBD50", "#FF707F")) +
theme_pubr() 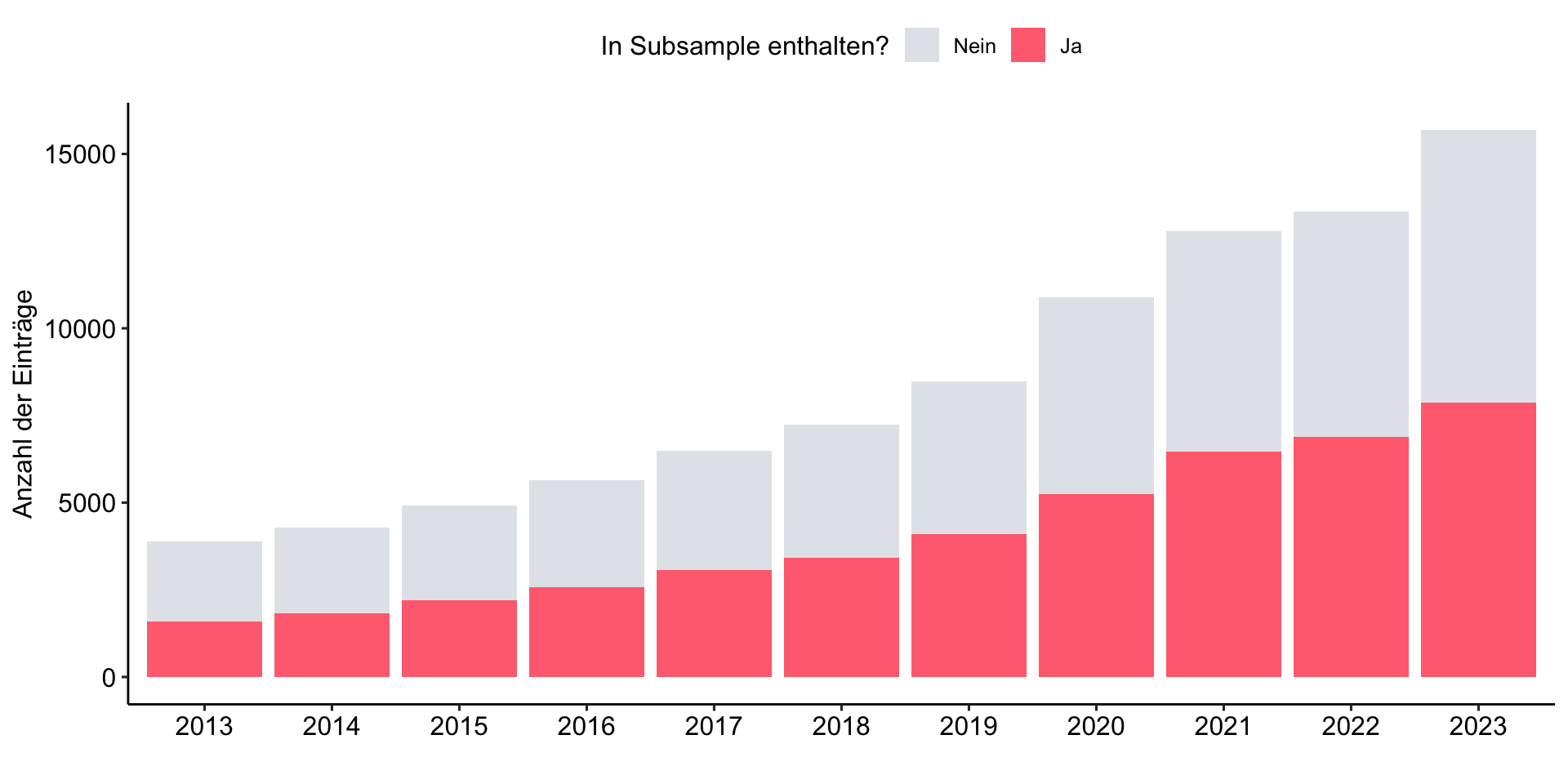
Explore abstracts
Tidy data principles als Grundlage für Analyse-Workflow

- Tidy data struture (each variable is column, each observation a row, each value is a cell, each type of observaional unit is a table) results in a table with one-token-per-row (Silge & Robinson, 2017).
The (Unavoidable) Word Cloud
Visualization of Top 50 token

Mehr als nur ein Wort
Modellierung von Wortzusammenhängen: n-grams and correlations
Viele der wirklich interessanten Ergebnisse von Textanalysen basieren auf den Beziehungen zwischen Wörtern, z.B.
- welche Wörter dazu “neigen”, unmittelbar auf einander zu folgen (n-grams),
- oder innerhalb desselben Dokuments gemeinsam aufzutreten (Korrelation)
Spezifische “Partner” in spezifischen Umgebungen
Häufig auftretenden Wörter in der Umgebung von review, literature, systematic
review_pairs_corr %>%
filter(
item1 %in% c(
"review",
"literature",
"systematic")
) %>%
group_by(item1) %>%
slice_max(correlation, n = 5) %>%
ungroup() %>%
mutate(
item2 = reorder(item2, correlation)
) %>%
ggplot(
aes(item2, correlation, fill = item1)
) +
geom_bar(stat = "identity") +
facet_wrap(~ item1, scales = "free_y") +
coord_flip() +
scale_fill_manual(
values = c(
"#04316A",
"#C50F3C",
"#00B2D1")) +
theme_pubr()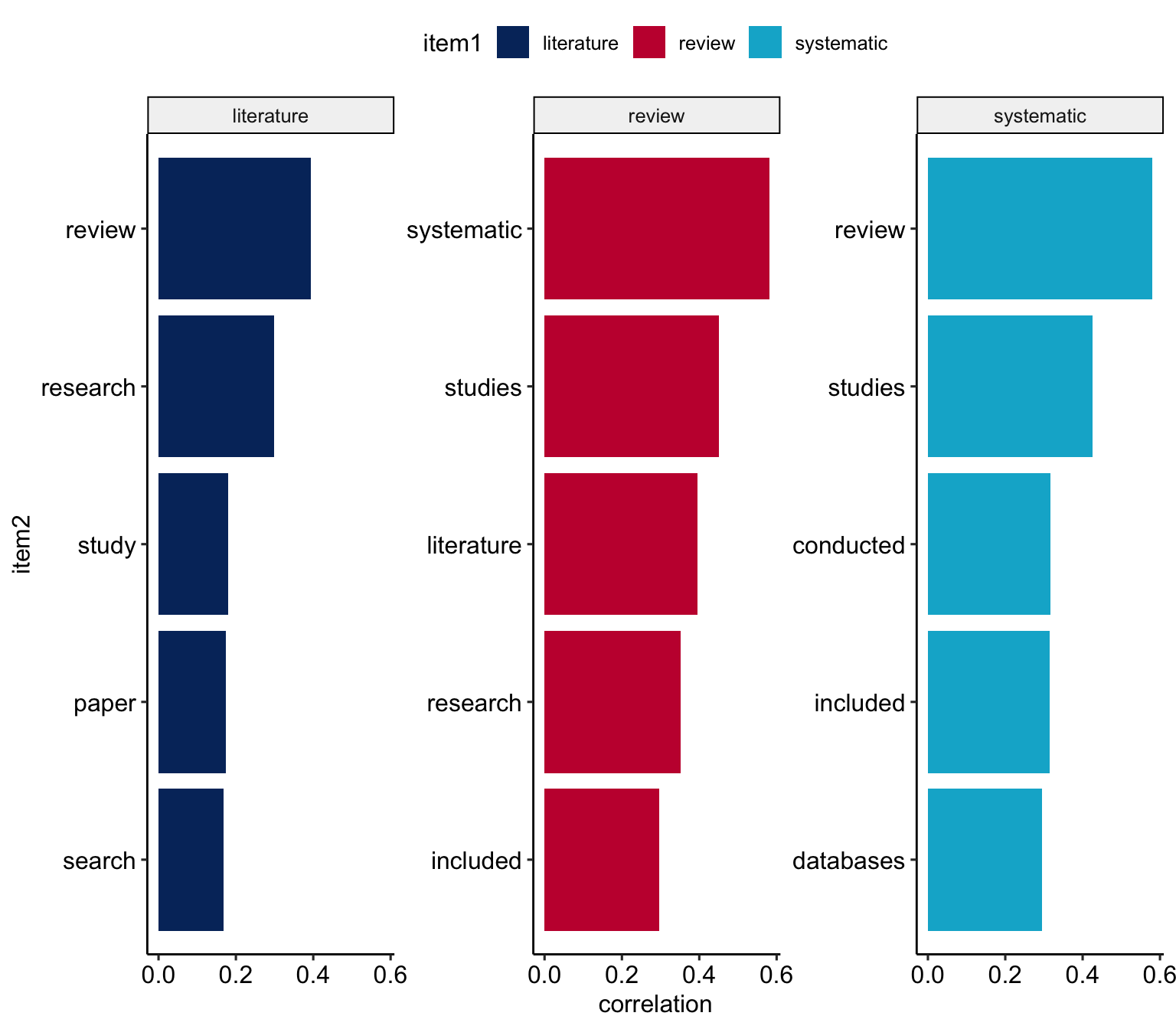
Let’s talk about sentiments
Dictionary based approach of text analysis
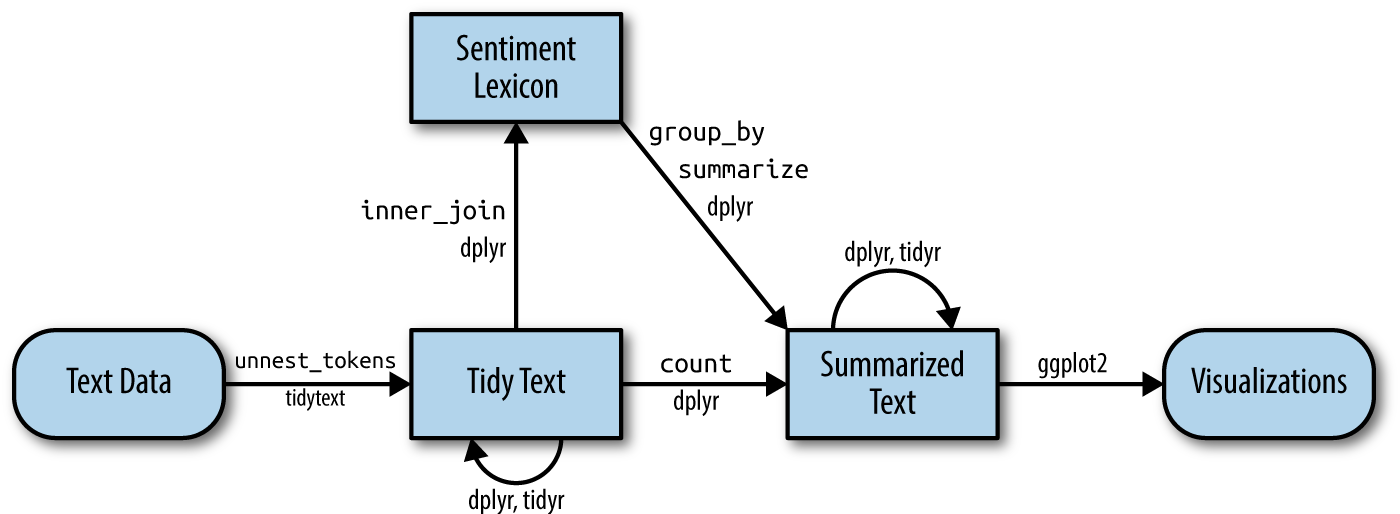
Atteveldt et al. (2021) argue that sentiment, in fact, are quite a complex concepts that are often hard to capture with dictionaries.
Über die Bedeutung von “positiv;negativ”
Die häufigsten “positiven” und “negativen” Wörter in den Abstracts
review_sentiment_count <- review_tidy %>%
inner_join(
get_sentiments("bing"),
by = c("text" = "word"),
relationship = "many-to-many") %>%
count(text, sentiment)
# Preview
review_sentiment_count %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(text = reorder(text, n)) %>%
ggplot(aes(n, text, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(
~sentiment, scales = "free_y") +
labs(x = "Contribution to sentiment",
y = NULL) +
scale_fill_manual(
values = c("#C50F3C", "#007900")) +
theme_pubr()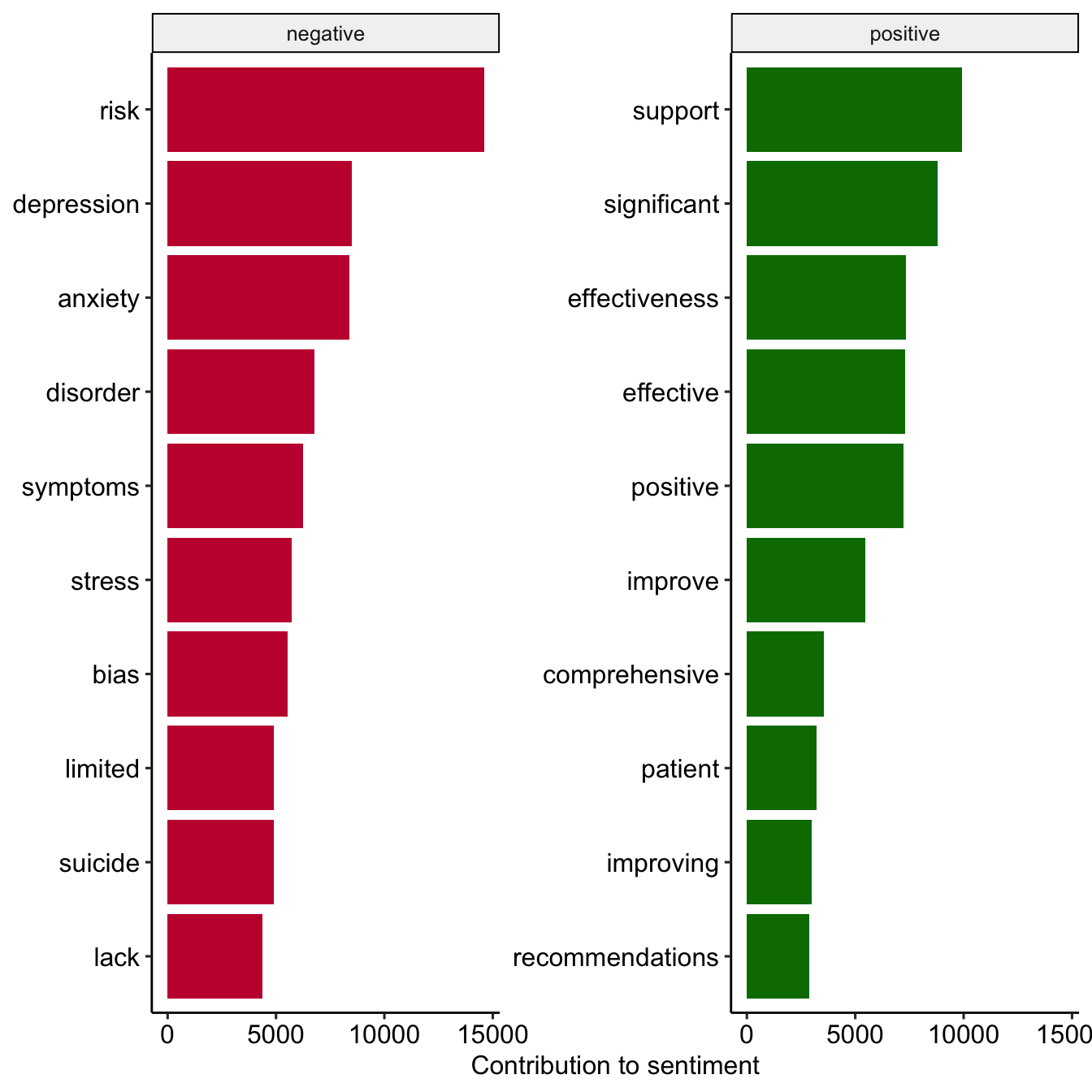
Neutral, mit einem leicht “negativen” Unterton
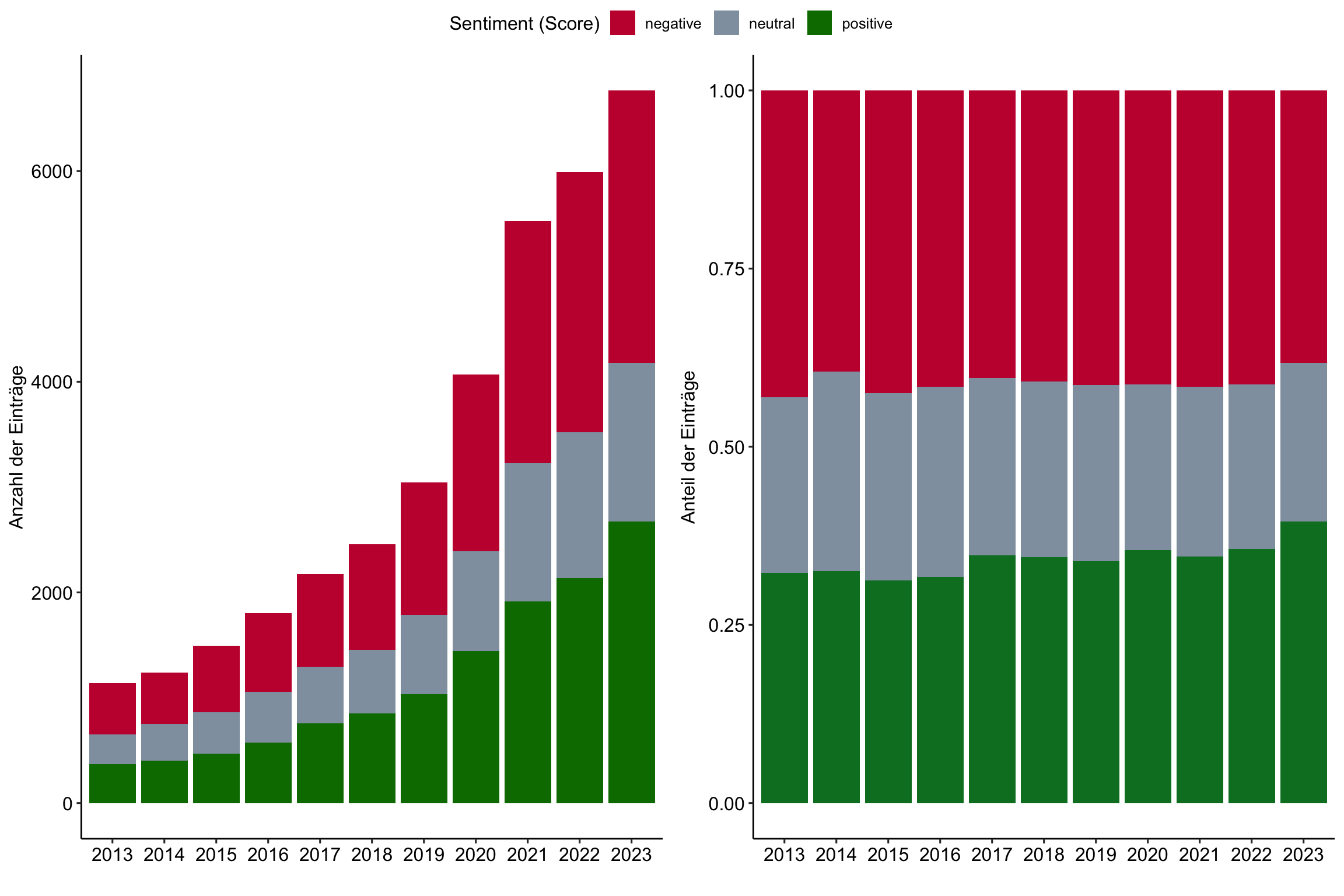
Verteilung des Sentiment (Scores) in den Abstracts
[1] 0.4858737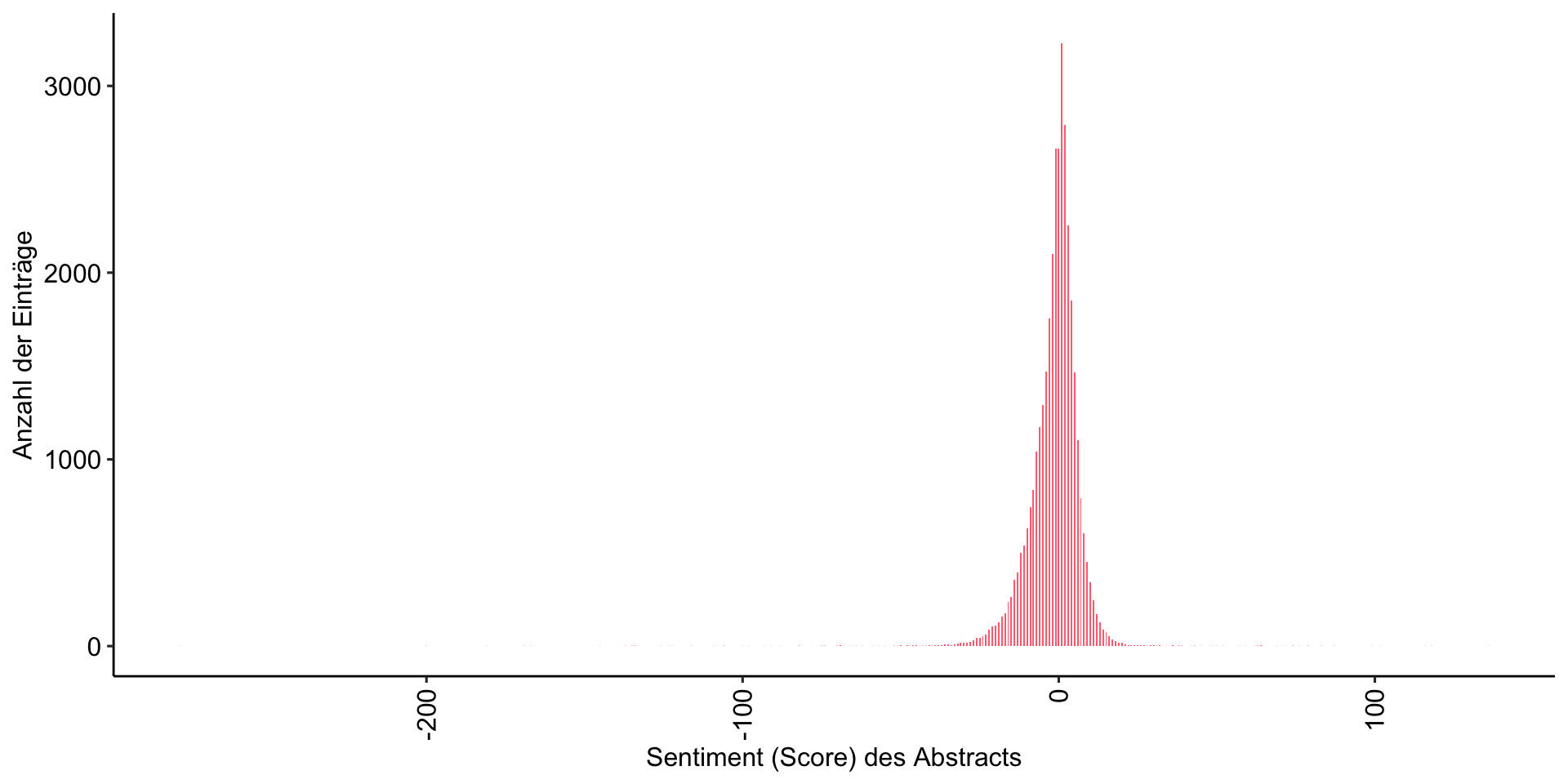
Keep it neutral
Entwicklung des Sentiment (Scores) der Abstracts im Zeitverlauf
Expand for full code
# Create first graph
g1 <- review_works_correct %>%
filter(id %in% review_sentiment$id) %>%
left_join(review_sentiment, by = join_by(id)) %>%
sjmisc::rec(
sentiment,
rec = "min:-2=negative; -1:1=neutral; 2:max=positive") %>%
ggplot(aes(x = publication_year_fct, fill = as.factor(sentiment_r))) +
geom_bar() +
labs(
x = "",
y = "Anzahl der Einträge",
fill = "Sentiment (Score)") +
scale_fill_manual(values = c("#C50F3C", "#90A0AF", "#007900")) +
theme_pubr()
#theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
# Create second graph
g2 <- review_works_correct %>%
filter(id %in% review_sentiment$id) %>%
left_join(review_sentiment, by = join_by(id)) %>%
sjmisc::rec(
sentiment,
rec = "min:-2=negative; -1:1=neutral; 2:max=positive") %>%
ggplot(aes(x = publication_year_fct, fill = as.factor(sentiment_r))) +
geom_bar(position = "fill") +
labs(
x = "",
y = "Anteil der Einträge",
fill = "Sentiment (Score)") +
scale_fill_manual(values = c("#C50F3C", "#90A0AF", "#007D29")) +
theme_pubr()
# COMBINE GRPAHS
ggarrange(g1, g2,
nrow = 1, ncol = 2,
align = "hv",
common.legend = TRUE)