| Session | Datum | Topic | Presenter |
|---|---|---|---|
Introduction |
|||
1 |
25.10.2023 |
Kick-Off |
Christoph Adrian |
01.11.2023 |
🎃 Holiday (No Lecture) |
||
2 |
08.11.2023 |
Einführung in DBD |
Christoph Adrian |
3 |
15.11.2023 |
🔨 Working with R |
Christoph Adrian |
🗣️ |
Presentations |
||
4 |
22.11.2023 |
📚 Media routines & habits |
Group C |
5 |
29.11.2023 |
📚 Digital disconnection |
Group A |
6 |
06.12.2023 |
📦 Data collection methods |
Group D |
7 |
13.12.2023 |
📦 Automatic text analysis |
Group B |
8 |
20.12.2023 |
Buffer Session |
|
🎄Christmas Break (No Lecture) |
|||
📂 Project |
Analysis of media content |
||
9 |
10.01.2024 |
🔨 Text as data |
Christoph Adrian |
10 |
17.01.2024 |
🔨 Topic Modeling |
Christoph Adrian |
11 |
24.01.2024 |
🔨 Q&A |
Christoph Adrian |
12 |
31.01.2024 |
📊 Presentation & Discussion |
All groups |
13 |
07.02.2024 |
🏁 Recap, Evaluation & Discussion |
Christoph Adrian |
🔨 Working with R
Session 03
15.11.2023
Buliding best practice
Willkommen (zurück) zu R
How most academics learn R:

How you should learn R:
- Versuchen Sie R nicht systematisch zu lernen, sondern spezifisch anzuwenden.
- Organisieren Sie Ihre Arbeit in R (mit Projekten)
- Schreiben Sie lesbaren und nachvollziehbaren Code!
- Fragen Sie nach!
Ein Repository voller Daten
Beispiel für Übung durch Anwendung: tidytuesday (social data project)
Data is posted to social media every Monday morning.
Explore the data, watching out for interesting relationships.
Create a visualization, a model, a shiny app, or some other piece of data-science-related output, using R or another programming language.
Share your output and the code used to generate it on social media with the #TidyTuesday hashtag.
Everything you need in one place
Organisation der Arbeit mit RStudio-Projekten
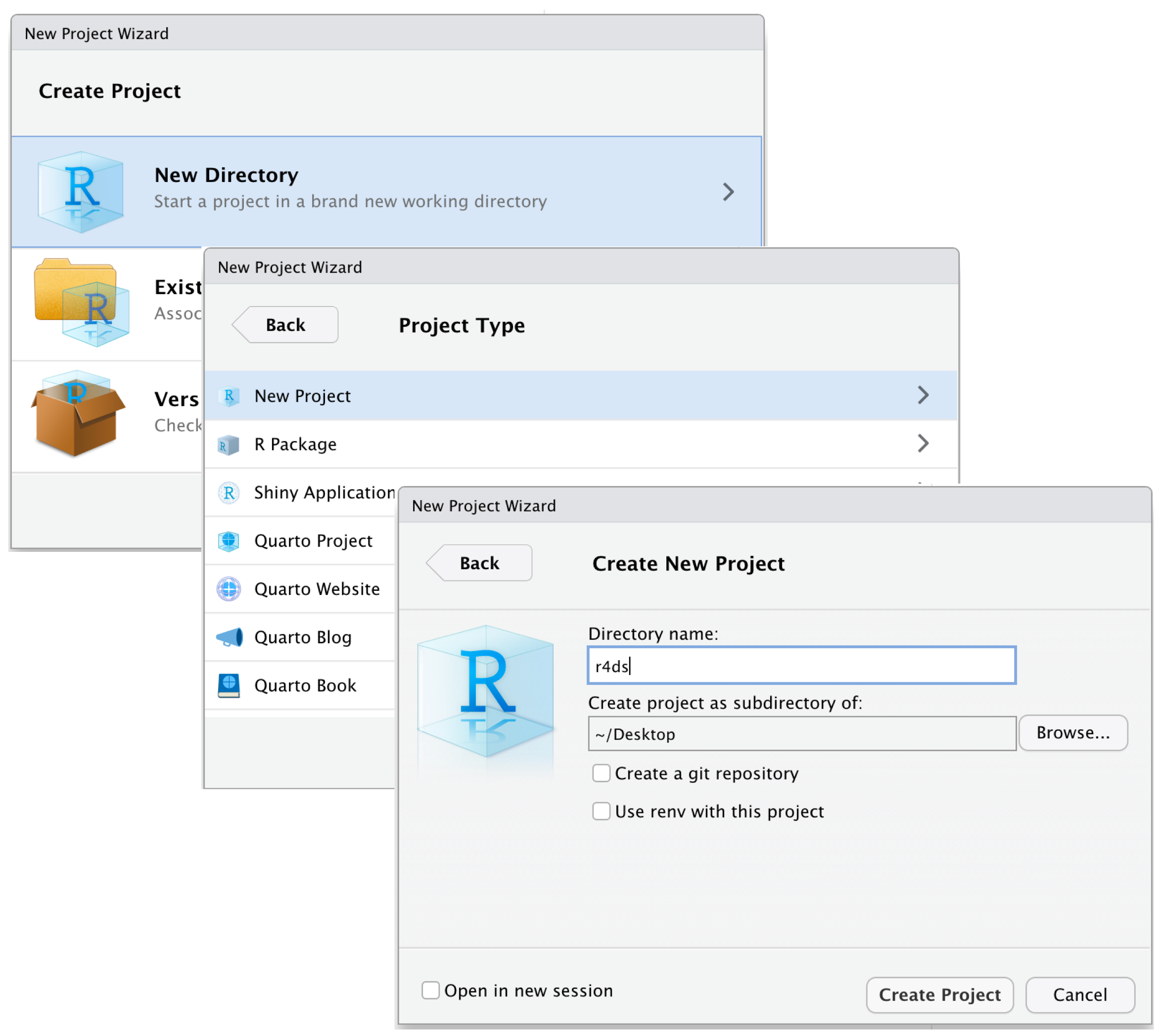
Versionskontrolle als Kür
Crashkurs zu Git(Hub)
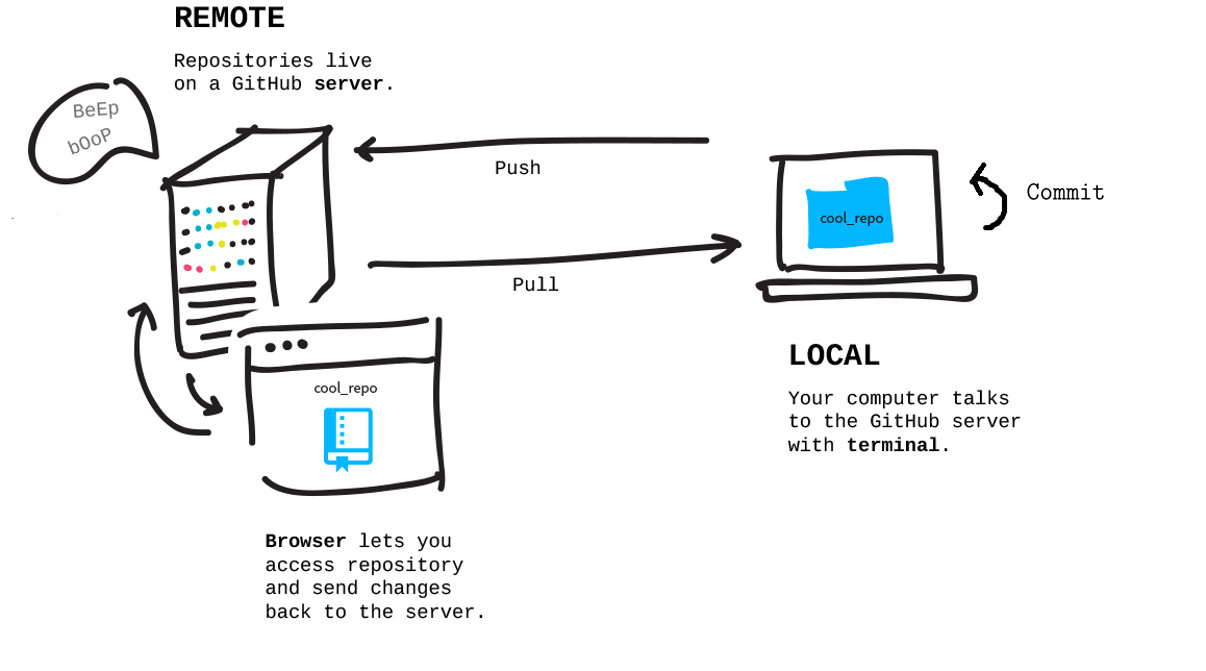
- Versionkontrolle für Code, gesichert in der Cloud
- Vollständige Rückverfolgbarkeit von (gesicherten) Änderungen
- Great effort, great return.
Run chunks, not (whole) scripts
Outputorientiertes Coding mit Quarto
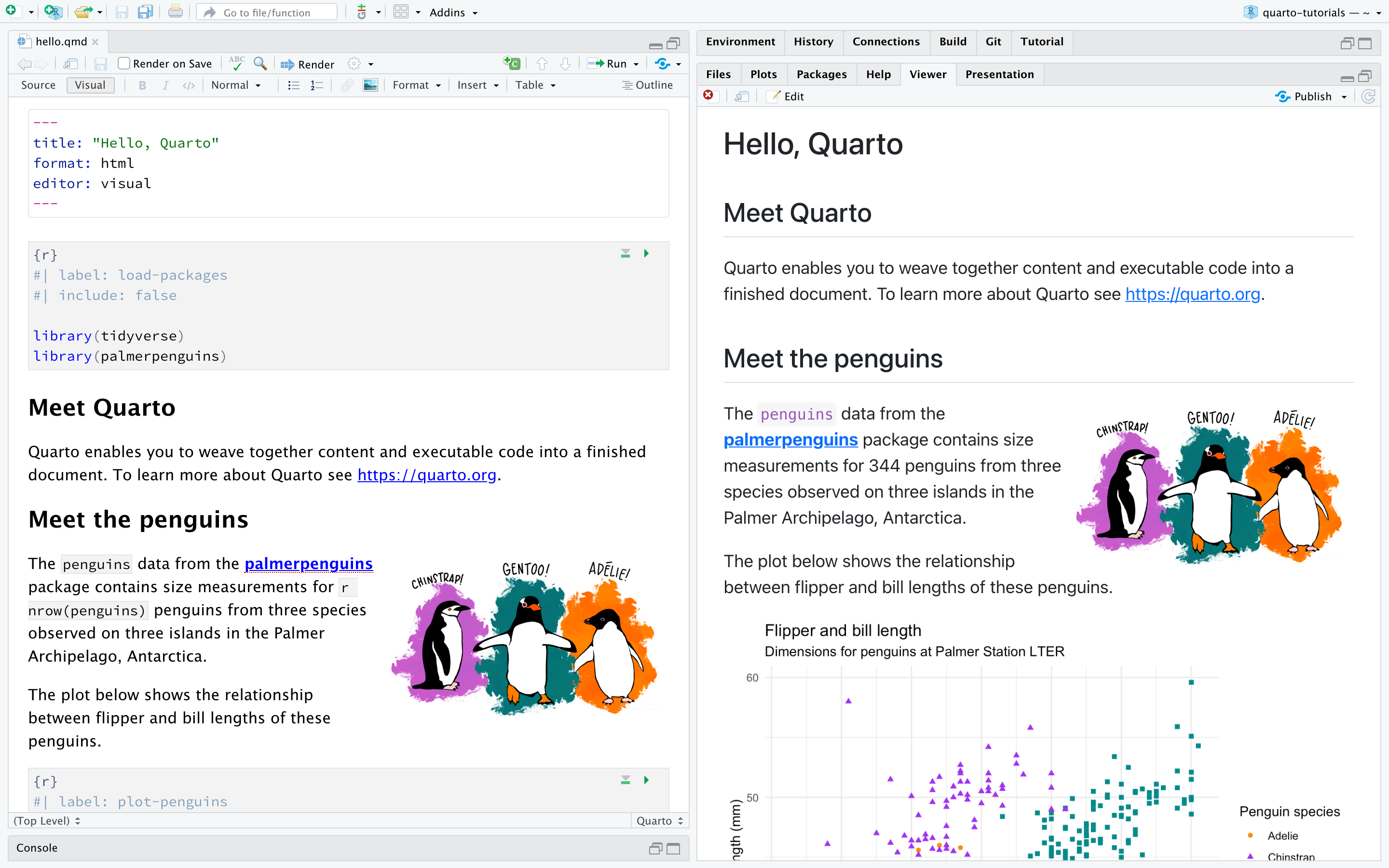
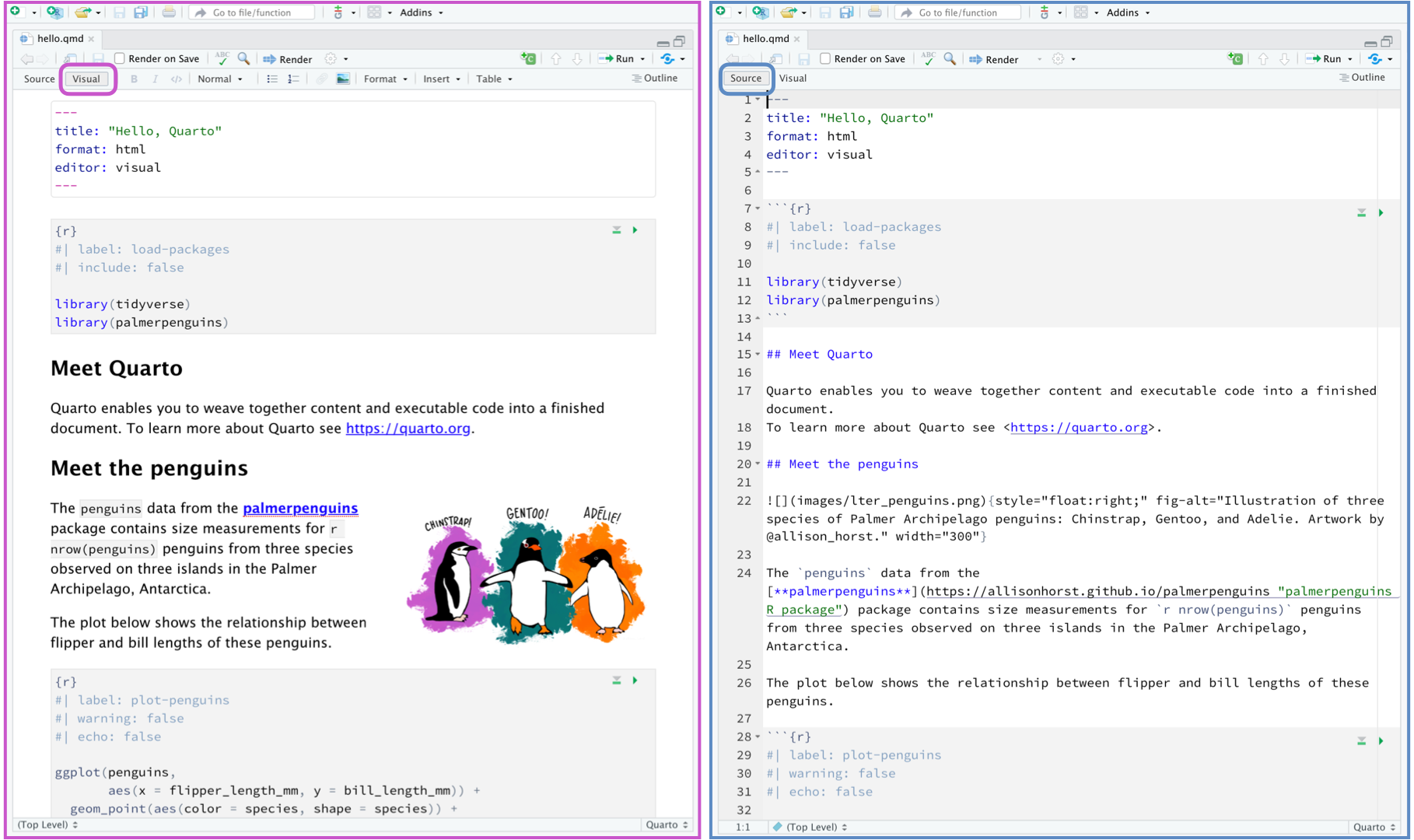
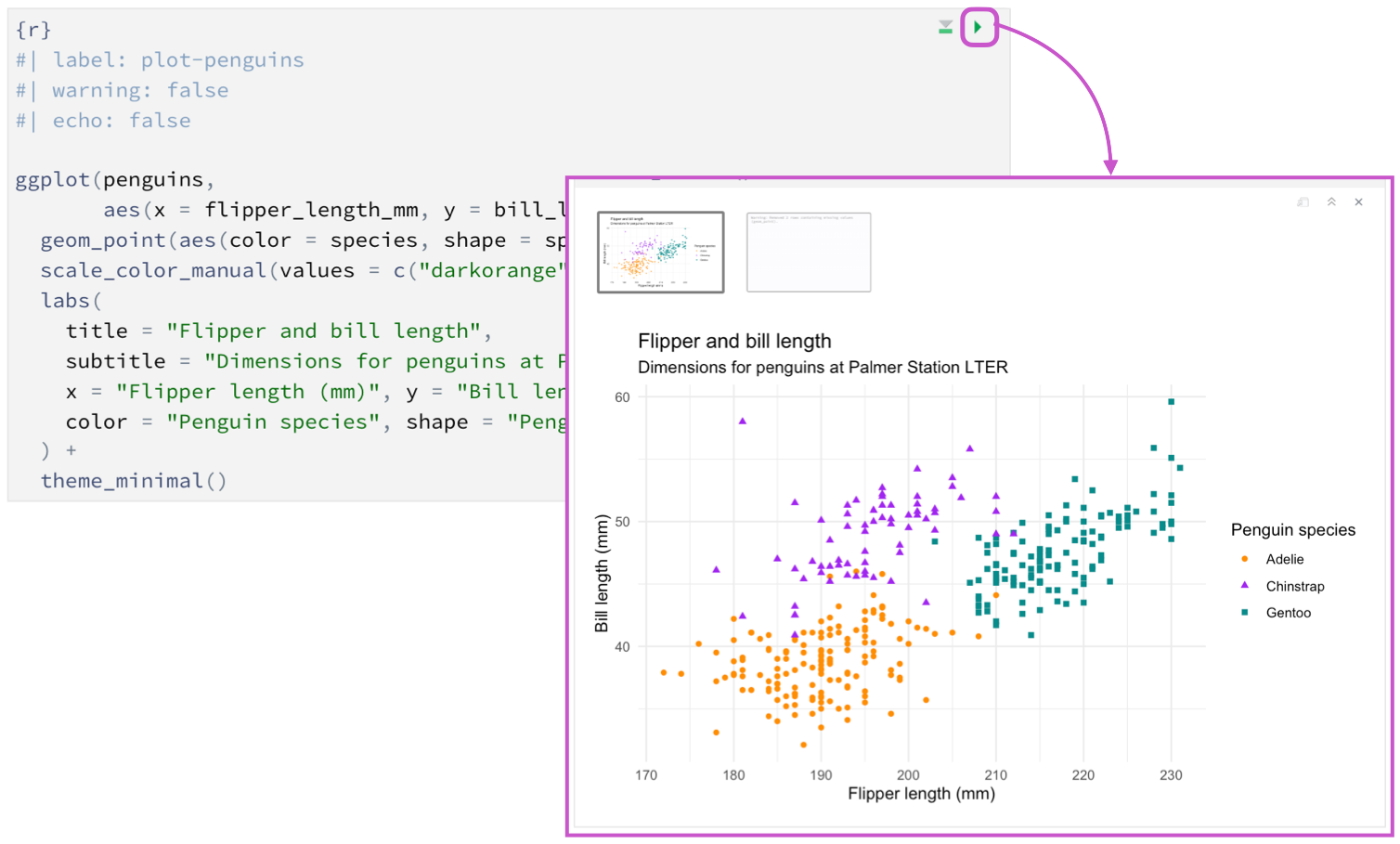
RScript ≤ RMarkdown ≤ Quarto
Der Weg vom Code zum Output

Grundidee von Quarto
![]() : ein Quelldokument kann in eine Vielzahl von Ausgabeformaten umgewandelt werden
: ein Quelldokument kann in eine Vielzahl von Ausgabeformaten umgewandelt werdenMarkdown-Syntax für Text, verschiedene Programmiersprachen (wie z.B. R und Python) in einem Dokument
Empfehlung: tidyverse is your friend!
Verschiedenen Paketen für alle Schritte eines Projektes
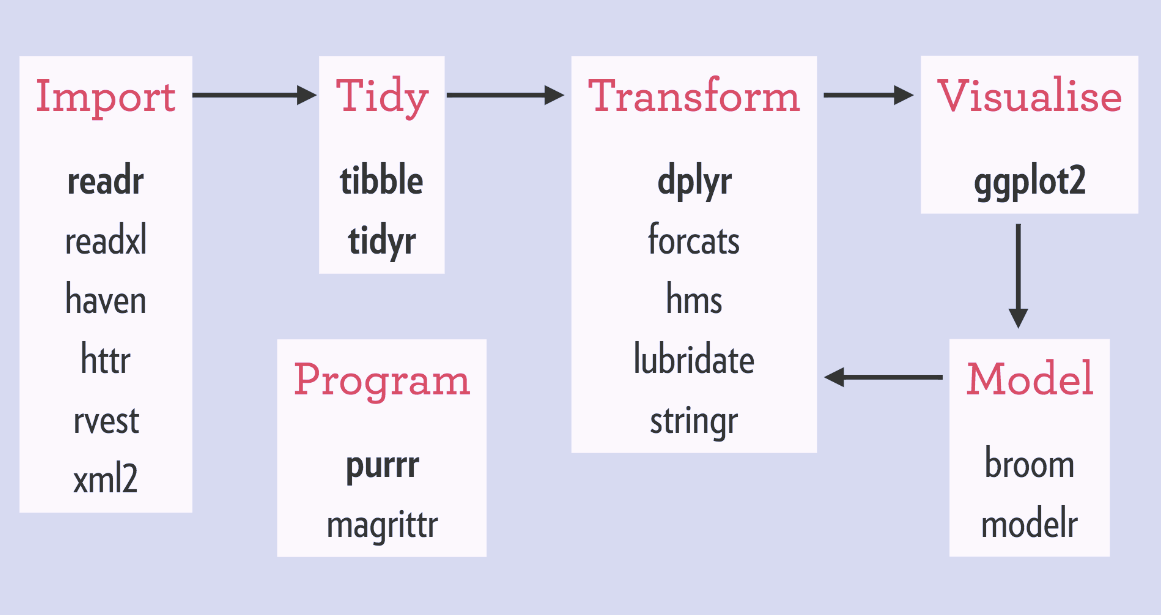
Quelle: RStudio
The friend of your friend: easystats
Fokus auf die Analyse
Quelle: Lüdecke et al. (2022)
Working with R …
… in the real world!
Im Fokus: Hollywood Age Gap Project
![]()
![]()
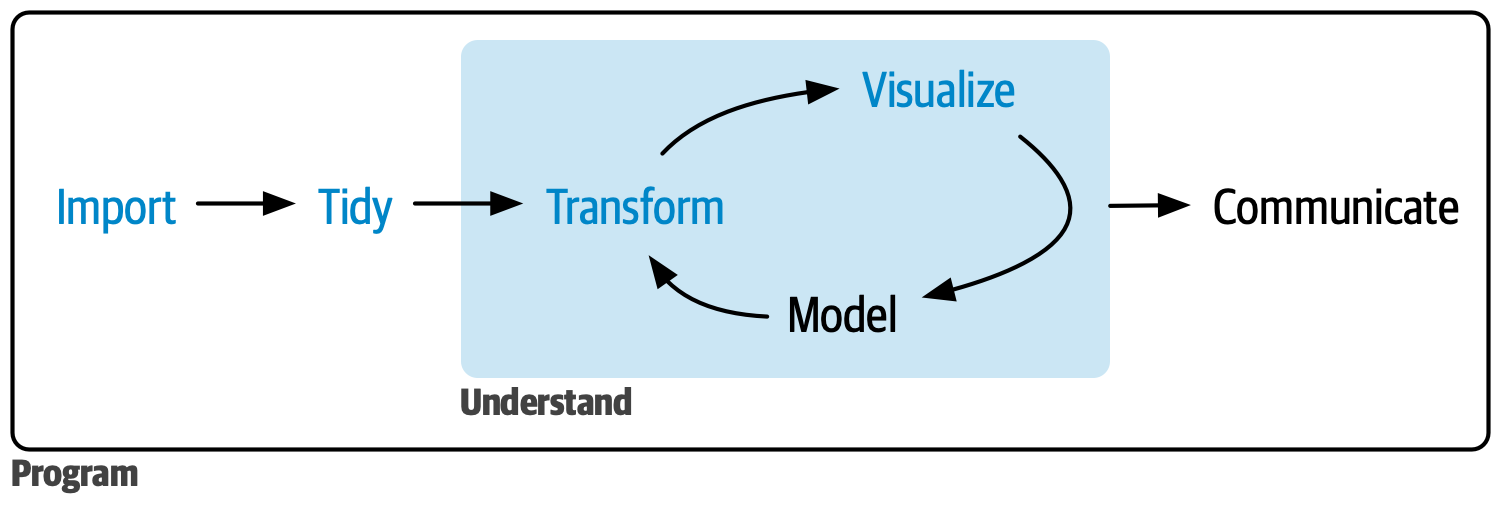
Am Anfang steht die Theorie
Typischer “data science process” als Kontext der Sitzung
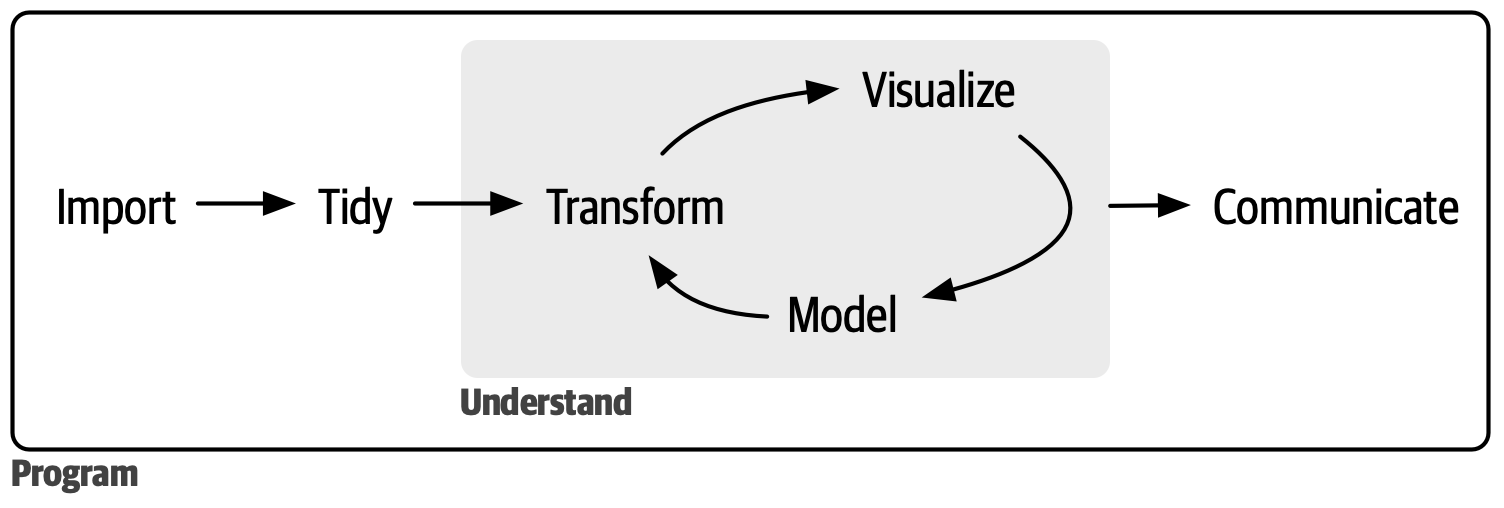
Quelle: Wickham et al. (2023)
Age difference in years between move love interests
Datengrundlage für die Beispiele: Hollywood Age Gap ( | )
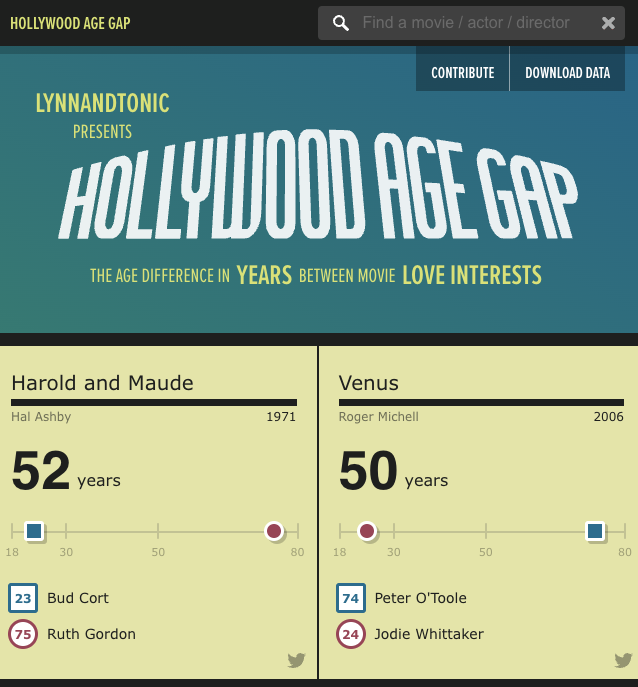
- “An informational site showing the age gap between movie love interests.”
- Community-Projekt
Guidlines for participation/submission:
- The two (or more) actors play actual love interests (not just friends, coworkers, or some other non-romantic type of relationship)
- The youngest of the two actors is at least 17 years old
- Not animated characters
Explore ➞ Adapt ➞ Repeat ⟳
Prozess der Datenaufbereitung
- nimmt in der Regel den Großteil der Zeit der Datenanalyse in Anspruch
- häufig bedarf es der mehrfachen Wiederholung dreier Schritte:
- der (explorativen)
Erkundung, - der
Standartdisierungund - der (erneuten)
Bereinungder Daten
- der (explorativen)
Drei Stufen der Datenqualität
Typische Strategien zur Datenbereinigung nach Pearson (2018)

Bewertung allgemeiner Merkmale des Datensatzes, z. B.:
Wie viele Fälle sind enthalten? Wie viele Variablen?
Wie lauten die Variablennamen? Sind sie sinnvoll?
Welchen Typ hat jede Variable, z. B. numerisch, kategorisch, logisch?
Wie viele eindeutige Werte hat jede Variable?
Welcher Wert tritt am häufigsten auf, und wie oft kommt er vor?
Gibt es fehlende Werte? Wenn ja, wie häufig ist dies der Fall?
Untersuchung deskriptiver Statistiken für jede Variable;
Explorative Visualisierung;
Verschiedene Verfahren zur Suche nach Anomalien in den Daten;
Untersuchung der Beziehungen zwischen Schlüsselvariablen mit Hilfe von Scatterplots/Boxplots/Mosaic-Plots;
Dokumentation des Vorgehens und der Ergebnisse (z.B. mit .rmd-Dokument). Dient als Grundlage für die anschließende Analyse und Erläuterung der Ergebnisse.
Let’s start exploring!
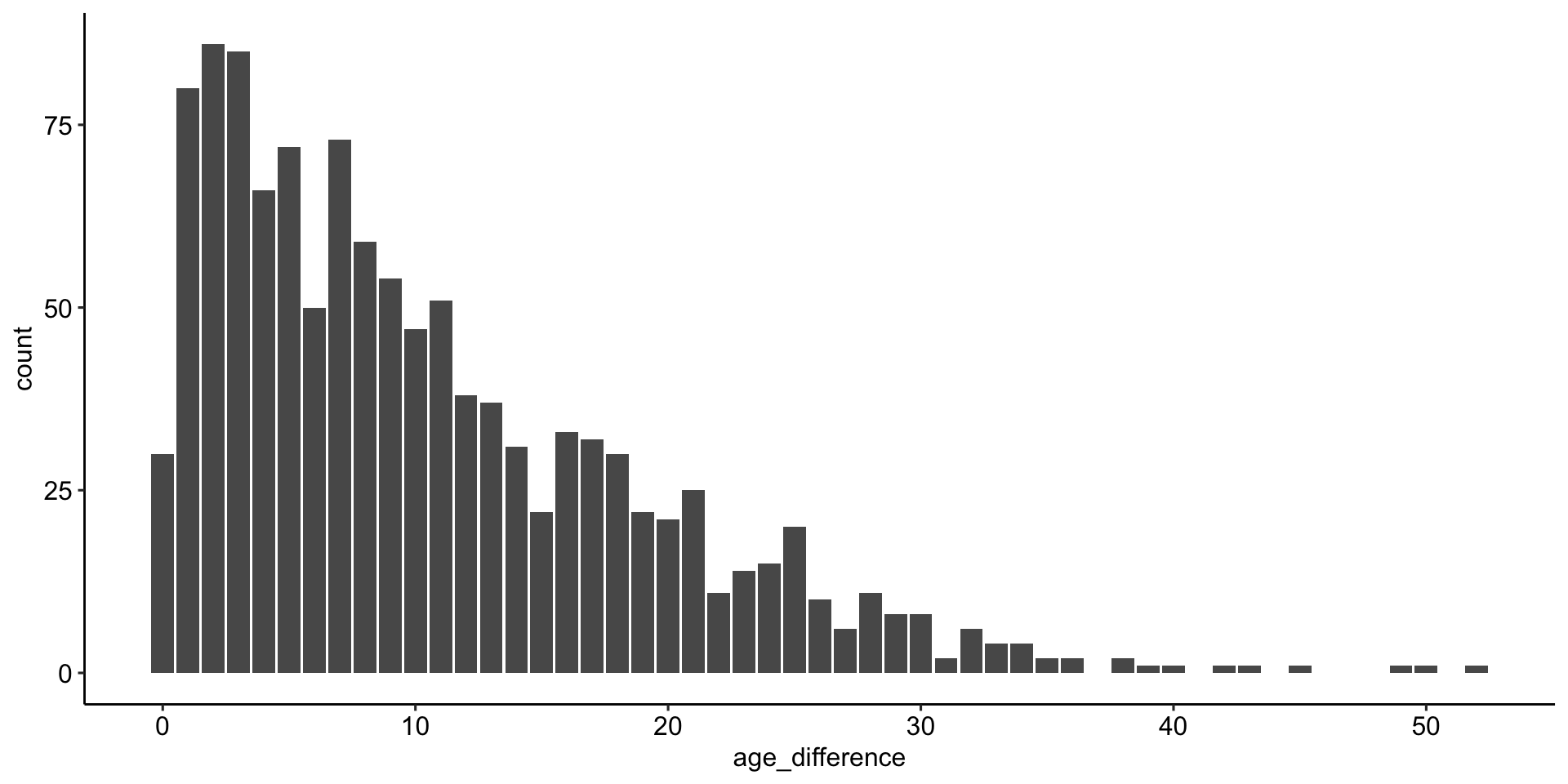
Wie sind die Altersunterschiede verteilt?
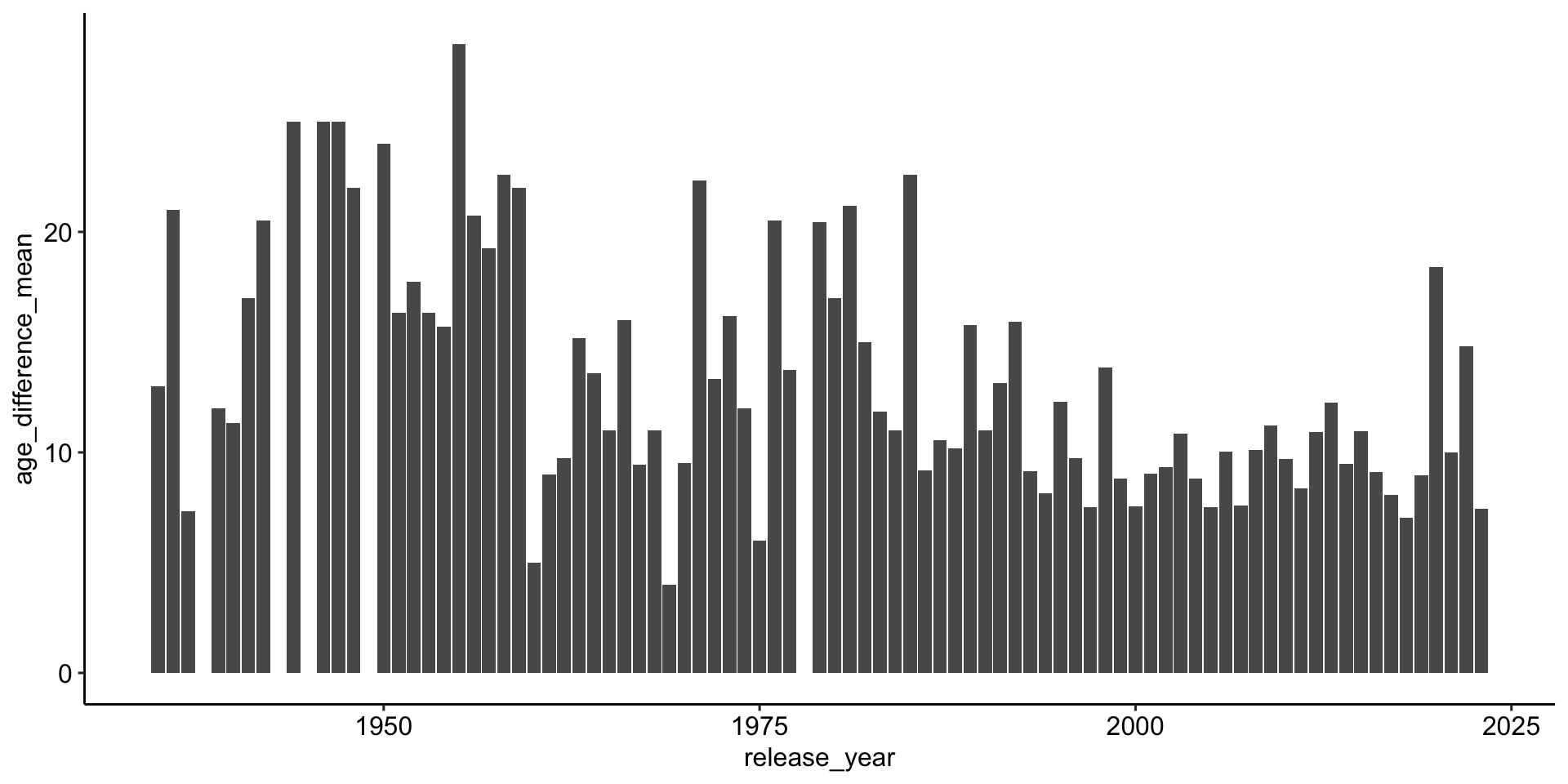
(Durchschnitts-)Unterschied nach Jahren
Gibt es einen Zusammenhang zwischen Altersunterschied und Releasedatum?
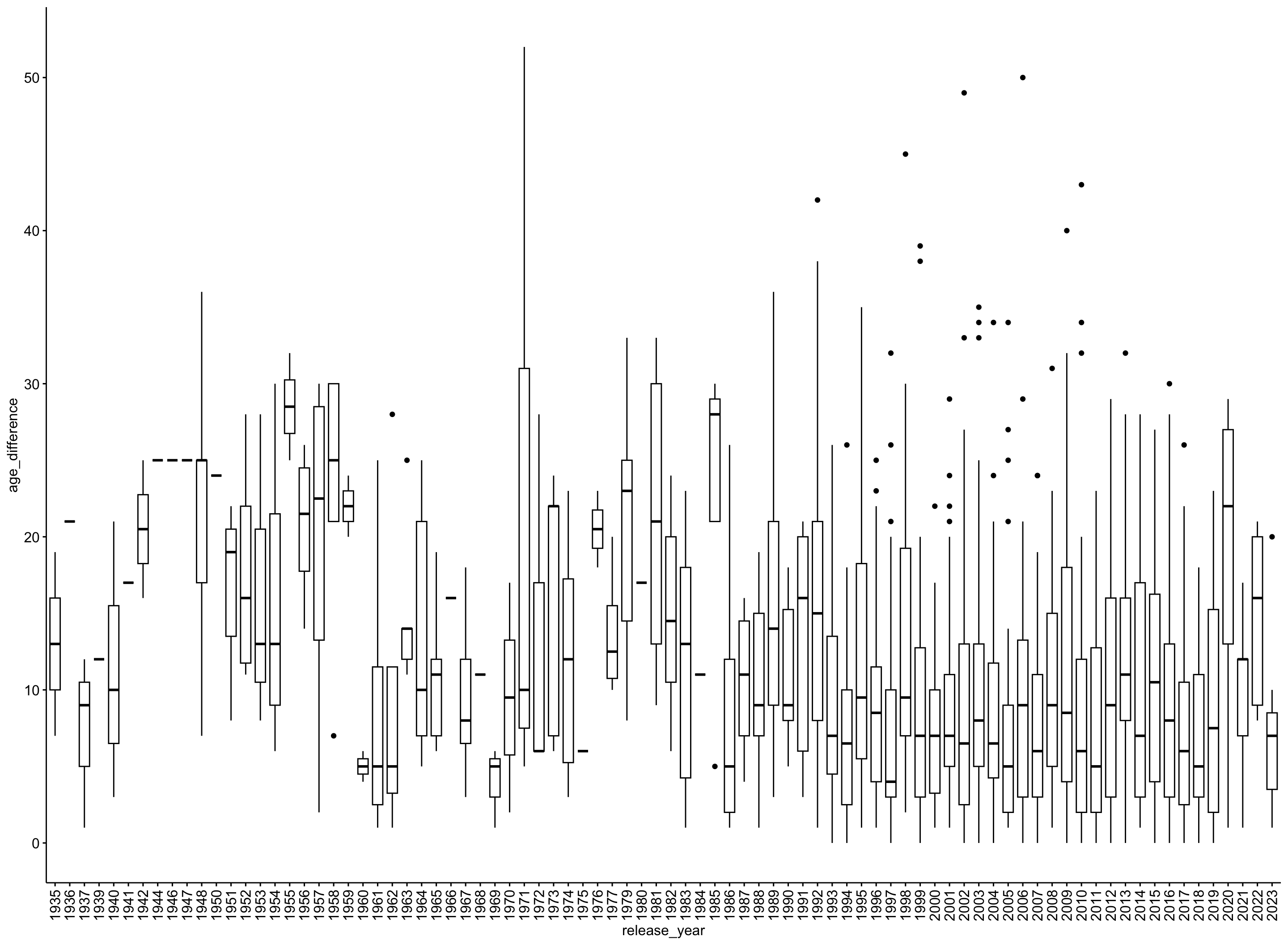
Verteilung nach Jahren
Gibt es einen Zusammenhang zwischen Altersunterschied und Releasedatum?
Try - fail - repeat
Kurzes Fazit der heutigen Sitzung
Wenn R, dann mit RStudio + Quarto!
Anschauen - nachmachen - ausprobieren
Keep it
tidy(Gute) Routinen bilden
“There is almost always a package for that …”

Literatur
Jonge, E. de, & Loo, M. van der. (2013). An introduction to data cleaning with R.
Lüdecke, D., Ben-Shachar, M. S., Patil, I., Wiernik, B. M., Bacher, E., Thériault, R., & Makowski, D. (2022). Easystats: Framework for easy statistical modeling, visualization, and reporting. CRAN. https://easystats.github.io/easystats/
Pearson, R. K. (2018). Exploratory data analysis using r. CRC Press/Taylor & Francis Group.
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: import, tidy, transform, visualize, and model data (2nd edition). O’Reilly.
